https://www.tensorflow.org/guide/tensor?hl=zh-cn
我用的是Tensorflow2.4.1,CUDA11.1,cudnn-11.1,Python3.7,Vs2019,Win10
Tensor与常量
一维二维三维,我索性理解成长宽高。某类数据的集合。一种数据集合形式。
例如音频的高低,图像的色彩,双色球的数字,人的文字,但是它们是有规律的,某种特征。
它有什么用,我还不知道,总之只要有想象力,我相信就会有一席之地。
它的历史,找不到任何对我有用的东西。它的编译原理,让我想起JVM,SPRING,总之图片很抽象。
初步使用
import tensorflow as tf
x = [[2.]]
'''
matmul含义为矩阵相乘,2*2=4 ,所以m = [[4.]]
m = tf.matmul(x, x)
'''
print("hello, {}".format(m))
'''
executing_eagerly(),翻译也不明白是个啥,懂这个执行更快就是
'''
print(tf.executing_eagerly())
'''
hello, [[4.]]
True
'''打印Tensor
import tensorflow as tf
a = tf.constant([[1, 2],
[3, 4]])
print(a)
'''
tf.Tensor(
[[1 2]
[3 4]], shape=(2, 2), dtype=int32)
shape:形状 一个长为2,宽为2的二维数组,dtype: data type 为整形32位
'''
b = tf.add(a, 3)
print(b)
'''
tf.Tensor(
[[4 5]
[6 7]], shape=(2, 2), dtype=int32)
tf.add() ,将数组的所有节点的值加上3
'''
m = tf.matmul(a, b)
print(m)
'''
tf.Tensor(
[[16 19]
[36 43]], shape=(2, 2), dtype=int32)
matmul: matrix multiply
1*4+2*6,1*5+2*7
3*4+4*6, 3*5+4*7
第一行第一列的值:第1行各个数*第1列各个数
第一行第二列的值:第1行各个数*第2列各个数
第二行第一列的值:第2行各个数*第1列各个数
第二行第二列的值:第2行各个数*第2列各个数
'''
c = np.multiply(a, b)
print(c)
'''
[[ 4 10]
[18 28]]
1*4 , 2*5
3*6, 4*7
'''在内存里面我知道数组地址是连续的,我猜测在GPU里面地址也是连续的。
所谓的多维数组,相对显卡而言是一种抽象的概念。抽象有好处也有坏处,
对我来说,我更乐于直观看到本质,Tensorflow究竟在干什么?
在后面的教程里面我看到它把文字转成编码,编码转成数字。这个官网是真的慢的一逼。
规则的数据使用tf.convert_to_tensor()转换成张量
不规则的数据使用tf.ragged.constant()转换成张量
什么是不规则,例如:
import tensorflow as tf
ragged_list = [
[0, 1, 2, 3],
[4, 5],
[6, 7, 8],
[9]]
try:
tensor = tf.constant(ragged_list)
except Exception as e:
print(f"{type(e).__name__}: {e}")
# Can't convert non-rectangular Python sequence to Tensor.
ragged_tensor = tf.ragged.constant(ragged_list)
print(ragged_tensor)
#<tf.RaggedTensor [[0, 1, 2, 3], [4, 5], [6, 7, 8], [9]]>字符的转换
import tensorflow as tf
text = tf.constant("1 10 100")
print(tf.strings.to_number(tf.strings.split(text, " ")))
#如果有字符,会报错,要使用bytes_split,先拆分成字节,然后拆分成数字
byte_strings = tf.strings.bytes_split(tf.constant("Duck"))
byte_ints = tf.io.decode_raw(tf.constant("Duck"), tf.uint8)
print("Byte strings:", byte_strings)
print("Bytes:", byte_ints)
#对于unicode要使用unicode_split拆分
unicode_bytes = tf.constant("アヒル 🦆")
unicode_char_bytes = tf.strings.unicode_split(unicode_bytes, "UTF-8")
unicode_values = tf.strings.unicode_decode(unicode_bytes, "UTF-8")
print("\nUnicode bytes:", unicode_bytes)
print("\nUnicode chars:", unicode_char_bytes)
print("\nUnicode values:", unicode_values)自动构建矩阵
import tensorflow as tf
sparse_tensor = tf.sparse.SparseTensor(
indices=[[1, 2], [2, 3]],#标明数据位置
values=[21, 32],#标明数据的值
dense_shape=[3, 4])#标明矩阵的形状
print(sparse_tensor, "\n")
print(tf.sparse.to_dense(sparse_tensor))#矩阵自动填充#输出结果
SparseTensor(indices=tf.Tensor(
[[1 2]
[2 3]], shape=(2, 2), dtype=int64),
values=tf.Tensor([21 32], shape=(2,), dtype=int32),
dense_shape=tf.Tensor([3 4], shape=(2,), dtype=int64))
tf.Tensor(
[[ 0 0 0 0]
[ 0 0 21 0]
[ 0 0 0 32]], shape=(3, 4), dtype=int32)变量Variable
创建变量需要一个初始值,标明其类型,类型必须统一。
里面有一句:不过变量无法重构形状,应该是说重构形状会重新分配内存。
因为打印Copying and reshaping才理解其含义,想了很久,打印明明显示是可以进行重构的。
assign不能增加值,否则会报错,只能修改值,它的修改不会重构内存。
import tensorflow as tf
a = tf.Variable([2.0, 3.0])
# This will keep the same dtype, float32
a.assign([1, 2])
# Not allowed as it resizes the variable:
try:
a.assign([1.0, 2.0, 3.0])#只有两个位置,不能塞第三个值进去
except Exception as e:
print(f"{type(e).__name__}: {e}")#正确使用assign
a = tf.Variable([2.0, 3.0])
# 创建一个拷贝
b = tf.Variable(a)
a.assign([5, 6])
# b是a的拷贝,两个是有不同内存的
print(a.numpy())
print(b.numpy())
# assign_add和a.assign_sub会在原有的基础上进行修改
print(a.assign_add([2,3]).numpy()) # [7. 9.]
print(a.assign_sub([7,9]).numpy()) # [0. 0.]tf.Variable 如果没有对变量的引用,则会自动将其解除分配。
tf.Variable可以手动设置变量名,并且可以设置为相同,但名字相同不意味使用的为同一块内存空间。
保存和加载模型时会保留变量名。默认情况下,模型中的变量会自动获得唯一变量名,
所以除非您希望自行命名,否则不必多此一举。
指定变量常量的位置
with tf.device('CPU:0'): #意思是以上代码交给CPU运行
a = tf.Variable([[1.0, 2.0, 3.0], [4.0, 5.0, 6.0]])
b = tf.Variable([[1.0, 2.0, 3.0]])
with tf.device('GPU:0'): #意思应该是以下代码放到GPU上运行
k = a * b自动微分
Gradient梯度计算,当我看到3*3算出一个6的时候,既不是斜度,也不是高度面积,到底是啥。
Gradient在机器学习中,梯度是模型函数的偏导数向量。梯度指向最陡峭的上升路线。
于是我打开了bilibili,开始学习机器学习。
https://www.bilibili.com/video/BV1X541167yA?p=2&spm_id_from=pageDriver
线性回归:在一堆点之中找出一条尽量能穿过多数点的线,用来大致预测双色球。
这个概念有点道理,就如我爬山,刚开始兴致冲冲,爬上去满头大汗,爬普通的山真无聊。
这个关系,一个是步数,路程,高度,人的体力,有的步数,路高度特别高,这就需要大量体力。
有一天,我吃了没事做,想知道我爬到山腰想知道会消耗我多少体力,想起了线性回归。
可是有的小朋友,腿比我短,吃的比我少,爬的比我还快,大家都是人,这是怎么回事。
要是大家都能用到我的公式就好了,可是这个公式不够接近准确,就要大量的数据,和推导。
人去算这个数据实在是太累了,要是我能输入数据,机器自动算出多好,想起了Tensorflow
线性回归的损失函数:目标,找到一条尽可能在所有点中间的直线,以预测未来。
先表示出直线到每个点的平均距离,然后让这个平均距离最小,平均的东西,总是有点不可靠。
马云和我平均下来,这平均的也不是我的啊!平均是不够的,但是不能直接否定,部分还是很有用。
误差加上平方转化成统一的值,更好计算。假设函数减去真函数的值求平均数。。
这个方法被称为求损失的方法,求出最小损失。
导数还是梯度
回归y=x²,为什么会等于3呢?原来这个数是一个计算斜度函数的值。值越大,函数上升越猛。
曲线计算斜率,当x=2时,它的导向函数y = 2x,所以在y=x²,x=3时,对于导向函数的值为6
当然Tensorflow肯定不是套公式计算出来的,里面有个算法。
http://easymath.online/blogs/derivatives.php

计算y=x³,毫无疑问X=3的时候,肯定比y=x²斜度要大,究竟大多少呢。
import tensorflow as tf
x = tf.constant(3.0)
with tf.GradientTape() as g:
g.watch(x)#watch,监视这个张量
y = x*x*x
dy_dx = g.gradient(y, x)
print(dy_dx)
#tf.Tensor(27.0, shape=(), dtype=float32)
#斜度足足是y=x²的4倍多从入门到裂开
放弃是不可能的,只是我真的看不懂在写些什么?
- 获得训练数据。
- 定义模型。
- 定义损失函数。
- 遍历训练数据,从目标值计算损失。
- 计算该损失的梯度,并使用optimizer调整变量以适合数据。
- 计算结果。
Hello Tensorflow
在官网上面有一个新手入门的例子:
Mixed National Institute of Standards and Technology database:混合国家标准和技术研究所数据库
简称MNIST。它把图像和数字进行了拆分,例如1分成了一幅图像,和一个数字1.
分别压缩成了两个包,一个图像包,一个数字包,它们是互相对应,值和图像一一对应。
| 名称 | 我的解释 |
|---|---|
| train-labels-idx1-ubyte | 用于训练的数字包 |
| train-images-idx3-ubyte | 用于训练的图像包 |
| t10k-images-idx3-ubyte | 用于验证的图像包 |
| t10k-labels-idx1-ubyte | 用于验证的数字包, |
t10k的意思应为测试1000次,是个测试包,因为里面0-9的数字图像,都在在900到1000之间。
其中训练包一共10个数字包0-9,1个数字图像最少5400,最多6200张图像,格式为28*28=784
1.获得训练数据,我已经下载了4个gz包,然后加载数据
import numpy as np
import os
import gzip
import matplotlib.pyplot as plt
# 定义加载数据的函数,为保存gz数据的文件夹,该文件夹下有4个文件
# 'train-labels-idx1-ubyte.gz', 'train-images-idx3-ubyte.gz',
# 't10k-labels-idx1-ubyte.gz', 't10k-images-idx3-ubyte.gz'
def load_data(data_folder):
files = [
'train-labels-idx1-ubyte.gz', 'train-images-idx3-ubyte.gz',
't10k-labels-idx1-ubyte.gz', 't10k-images-idx3-ubyte.gz'
]
paths = []
for fname in files:
paths.append(os.path.join(data_folder,fname))
with gzip.open(paths[0], 'rb') as lbpath:
y_train = np.frombuffer(lbpath.read(), np.uint8, offset=8)
with gzip.open(paths[1], 'rb') as imgpath:
x_train = np.frombuffer(
imgpath.read(), np.uint8, offset=16).reshape(len(y_train), 28, 28)
with gzip.open(paths[2], 'rb') as lbpath:
y_test = np.frombuffer(lbpath.read(), np.uint8, offset=8)
with gzip.open(paths[3], 'rb') as imgpath:
x_test = np.frombuffer(
imgpath.read(), np.uint8, offset=16).reshape(len(y_test), 28, 28)
return (x_train, y_train), (x_test, y_test)
(train_images, train_labels), (test_images, test_labels) = load_data('E:/mnist/')
print(train_images.shape,train_labels.shape,test_images.shape,test_labels.shape)
print(train_labels[0],test_labels[0])
plt.imshow(train_images[0])
plt.show()
plt.imshow(test_images[0])
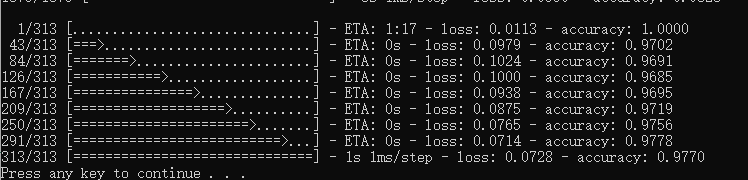
plt.show()打印结果为:
(60000, 28, 28) (60000,) (10000, 28, 28) (10000,)
5 7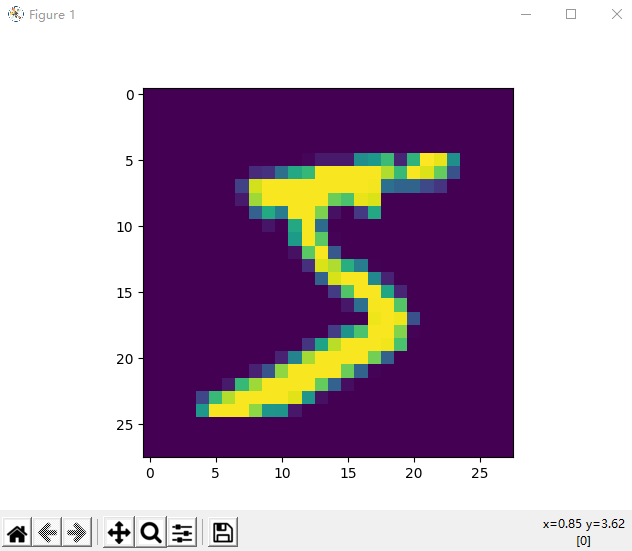
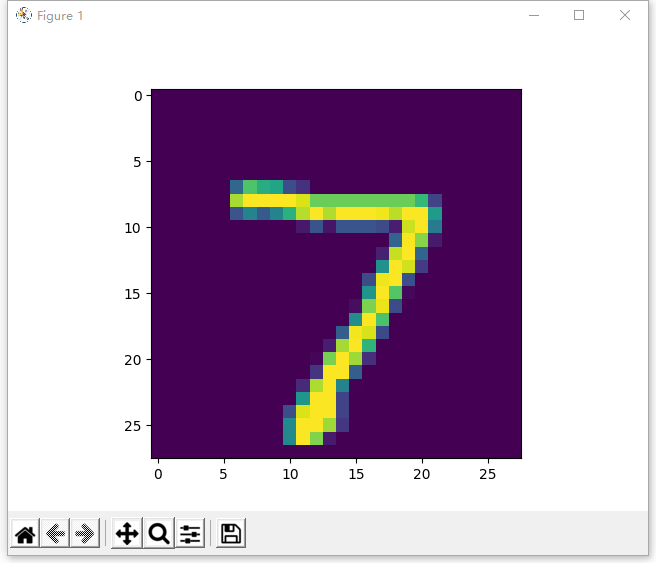
我表示非常吃惊,居然真这么巧60000张,10000张,压缩包里面明明每个数字的图片数量都不一样。
train包:5923+6742+5958+6131+5842+5421+5918+6265+5851+5949 = 60000
t10k包:980+1135+1032+1010+982+892+958+1028+974+1009=10000
import numpy as np
import os
import gzip
import tensorflow as tf
# 定义加载数据的函数,为保存gz数据的文件夹,该文件夹下有4个文件
# 'train-labels-idx1-ubyte.gz', 'train-images-idx3-ubyte.gz',
# 't10k-labels-idx1-ubyte.gz', 't10k-images-idx3-ubyte.gz'
def load_data(data_folder):
files = [
'train-labels-idx1-ubyte.gz', 'train-images-idx3-ubyte.gz',
't10k-labels-idx1-ubyte.gz', 't10k-images-idx3-ubyte.gz'
]
paths = []
for fname in files:
paths.append(os.path.join(data_folder,fname))
with gzip.open(paths[0], 'rb') as lbpath:
y_train = np.frombuffer(lbpath.read(), np.uint8, offset=8)
with gzip.open(paths[1], 'rb') as imgpath:
x_train = np.frombuffer(
imgpath.read(), np.uint8, offset=16).reshape(len(y_train), 28, 28)
with gzip.open(paths[2], 'rb') as lbpath:
y_test = np.frombuffer(lbpath.read(), np.uint8, offset=8)
with gzip.open(paths[3], 'rb') as imgpath:
x_test = np.frombuffer(
imgpath.read(), np.uint8, offset=16).reshape(len(y_test), 28, 28)
return (x_train, y_train), (x_test, y_test)
#1.读取数据
(train_images, train_labels), (test_images, test_labels) = load_data('E:/mnist/')
#图像255rgb的点全部转换成了1,0
train_images, test_images = train_images / 255.0, test_images / 255.0
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),#输入层,识别28*28的图片
tf.keras.layers.Dense(128, activation='relu'),#假设隐藏神经元个数为128个
tf.keras.layers.Dropout(0.1),#防止过度拟和
tf.keras.layers.Dense(10, activation='softmax')#输出层,一共10个结果0-9
])
model.compile(optimizer='adam',#算法,有很多个
loss='sparse_categorical_crossentropy',#损失函数
metrics=['accuracy'])#算子
model.fit(train_images, train_labels, epochs=5)#训练5个回合
model.evaluate(test_images, test_labels)