汇编与C
文章重点在于测试一些函数和数据类型是如何实现的。
自动抹去了函数加载过程,我看了半天也没看懂,有很多奇怪的操作!
编译环境VS2019,Debug,X86,程序均由cl.exe直接编译生成
类型强制转换
#include <stdio.h>
int main()
{
//基本类型测试
char t0 = 16;//mov byte ptr ss:[ebp-0x1], 0x10
short t1 = 16;//mov word ptr ss:[ebp-0x8], ax(0x10)
int t2 = 16;//mov dword ptr ss:[ebp-0x10], 0x10
float t3 = 16;//movss dword ptr:ss[ebp-0x14], xmm0(浮点数寄存器)
double t4 = 16;//movsd qword ptr ss:[ebp-0x4c], xmm0(浮点数寄存器)
long t5 = 16;//mov dword ptr ss:[ebp-0x28], 0x10
t0 = t1;//mov byte ptr ss:[ebp-0x1], cl(word ptr ss:[ebp-0x8] 高位会被舍去)
t1 = t2;//mov word ptr ss:[ebp-0x8], dx(dword ptr ss:[ebp-0x10] 高位会被舍去)
t2 = t3;//mov dword ptr ss:[ebp-0x10], eax(dword ptr ss:[ebp-0x14])
t3 = t4;//movss dword ptr ss:[ebp-0x14],xmm0(qword ptr ss:[ebp-0x4c])
t4 = t5;//movsd qword ptr ss:[ebp-0x4c],xmm0(dword ptr ss:[ebp-0x28])
/*
1)发现定义的变量16是放在代码里面的
2)t0,t1,t2...被翻译成了栈内存地址,定义的参数都会被入栈存储
ebp - 0x1的原因(这是存放t0数据的栈位置)
1)在执行调用Main函数后,main的地址会被入栈,ebp记录了main的地址
2)在我这里,栈是从高到低存储的
3)程序把main地址的下一个地址作为存取t0
4)仔细发现后,实际上在main函数里面定义的变量都是存在栈里面的
t0 = t1(从高类型转换成低类型)
1.把高位的数据移到一个低位寄存器里面
2.然后低位寄存器的值放到对应的栈地址
3.编译器通过舍弃高位来实现类型转换
*/
//指针测试
char *p0 = 16;//mov dword ptr ss:[ebp-0x2c],0x10
short *p1 = 16;//mov dword ptr ss:[ebp-0x18],0x10
int *p2 = 16;//mov dword ptr ss:[ebp-0x1c],0x10
float *p3 = 16;//mov dword ptr ss:[ebp-0x20],0x10
double *p4 = 16;//mov dword ptr ss:[ebp-0x24],0x10
long *p5 = 16;//mov dword ptr ss:[ebp-0x30],0x10
p0 = p1;//mov dword ptr ss:[ebp-0x2c],ecx(dword ptr ss:[ebp-0x18])
p1 = p2;//mov dword ptr ss:[ebp-0x18],edx(dword ptr ss:[ebp-0x1c])
p2 = p3;//mov dword ptr ss:[ebp-0x1c],eax(dword ptr ss:[ebp-0x20])
p3 = p4;//mov dword ptr ss:[ebp-0x20],ecx(dword ptr ss:[ebp-0x24])
p4 = p5;//mov dword ptr ss:[ebp-0x24],edx(dword ptr ss:[ebp-0x30])
/*
声明:在main函数里面
1)所有的指针地址都是存放在栈里面
2)指针的地址由编译器自动分配生成
3)指针的低类型转高类型,先把源地址的值拷贝到低位寄存器
4)低位寄存器的值在赋给目的指针所指向的内存空间
*/
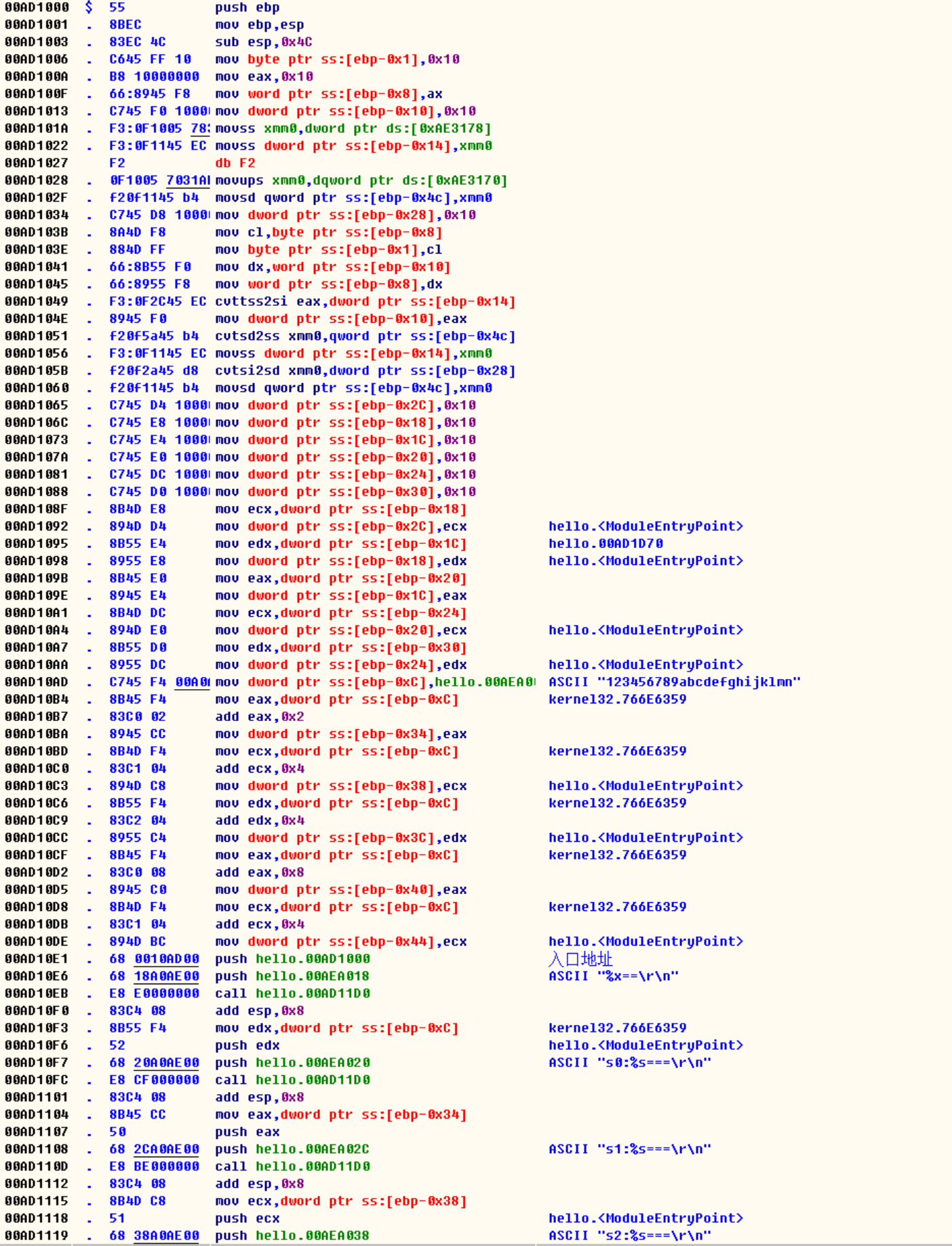
char *s0 = "123456789abcdefghijklmn";//mov dword ptr ss:[ebp-0xC],0xAEA000
char *s1 = (short*)s0 + 1;
//add eax(dword ptr ss:[ebp-0xC]),0x2
//mov dword ptr ss:[ebp-0x34],eax
char *s2 = (int*)s0 + 1;
//add ecx(dword ptr ss:[ebp-0xC]),0x4
//mov dword ptr ss:[ebp-0x38],ecx
char *s3 = (float*)s0 + 1;
//add edx(dword ptr ss:[ebp-0xC]),0x4
//mov dword ptr ss:[ebp-0x3C],edx
char *s4 = (double*)s0 + 1;
//add eax(dword ptr ss:[ebp-0xC]),0x8
//mov dword ptr ss:[ebp-0x40],eax
char *s5 = (long*)s0 + 1;
//add ecx(dword ptr ss:[ebp-0xC]),0x4
//mov dword ptr ss:[ebp-0x44],ecx
/*
1)我们所定义的'123456789abcdefghijklmn'没有存放在栈里面
2)编译器仅仅把字符串的地址拷贝到了指针的内存空间里面
3)定义的(short*...),发现它只是把字符串的地址产生了偏移
4)(short*)s0 +1 编译器直接把1和地址计算好了,翻译成了机器指令
5)short 两个字节, char一个字节,short - char + 1, 所以就是add ax, 2;
*/
printf("%x==\r\n", main);
printf("s0:%s===\r\n", s0);
printf("s1:%s===\r\n", s1);
printf("s2:%s===\r\n", s2);
printf("s3:%s===\r\n", s3);
printf("s4:%s===\r\n", s4);
printf("s5:%s===\r\n", s5);
printf("%x==\r\n", main);
system("pause");
}
普通类型与内存的关系

ebp = 007B F84C
char => ( 007B F84C - 0x1) = 007B F84B = 10;
short => ( 007B F84C - 0x8) = 007B F844 = 0010;
int => ( 007B F84C - 0x10) = 007B F83C = 0000 0010
float => ( 007B F84C - 0x14)007B F838 = 4080 0000
double => ( 007B F84C - 0x4C)007B F800 = 4030 0000 0000 0000
long => ( 007B F84C - 0x28)007B F824 = 0000 0010上面这个图你可能发现数据没有按顺序存储,而且不规律
实际上这是编译器干的,实际上我们下面写的变量也会存储到上图里面
里面那些5114 什么的,只是我还没有执行到那里
在我执行完整个代码后,这块内存区都会变成对应的数据
编译器会对数据进行智能整理位置
这幅图主要看内存与类型的关系
在VS2019, X86里面,所有的变量地址都是4个字节的
char => 8位,占一个字节
short => 16位,占两个字节
int => 32位, 占4个字节
float => 32位, 占4个字节
double => 64位, 占8个字节
long => 32位, 占4个字节
在VS2019, x86和x64环境里面,
long都是四个字节,long long都是8个字节
注意:我们在定义变量的时候,请注意数据清零,有的编译器并不不会给你干这个事
像VS2019,直接提示编译不通过,我试过强制编译,如果这个未定义的参数,
没有任何赋值而代入函数, 当作入参,这个入参在机器码里面根本不存在,
函数找不到机器码入参,导致后续代码全部乱了。所以使用未定义的参数
有一定几率会导致函数死机,函数找不到你这个入参地址,程序直接崩溃
清零,变量初始化是一件非常重要的事情
指针类型与内存的关系

ebp = 007B F84C
char* => ( 007B F84C - 0x2C) = 007B F820 = 0000 0010;
short* => ( 007B F84C - 0x18) = 007B F834 = 0000 0010;
int* => ( 007B F84C - 0x1C) = 007B F830 = 0000 0010
float* => ( 007B F84C - 0x20)007B F82C = 0000 0010;
double* => ( 007B F84C - 0x24)007B F828 = 0000 0010;
long* => ( 007B F84C - 0x30)007B F81C = 0000 0010;在VS2019, X86里面,所有的指针地址都是4个字节的
它们机器指令和普通类型的区别就是,它们所指向的内存空间是不同的
普通类型的内存空间大小是明确定义的
而指针所指向的内存空间大小是由指向的内存块决定
指针就是一个内存地址
在上面定义的16通通占用了4个字节,对应的数据里面全部都是0000 0010
注意:如果定义的指针数据是没有指向任何地址的,当作函数入参的时候
在VS2019里面这个指针编译出来,在机器码里面都找不到的,根本没有入栈
使用未定义的指针当作函数入参是会引起程序死机的
printf函数是如何执行的
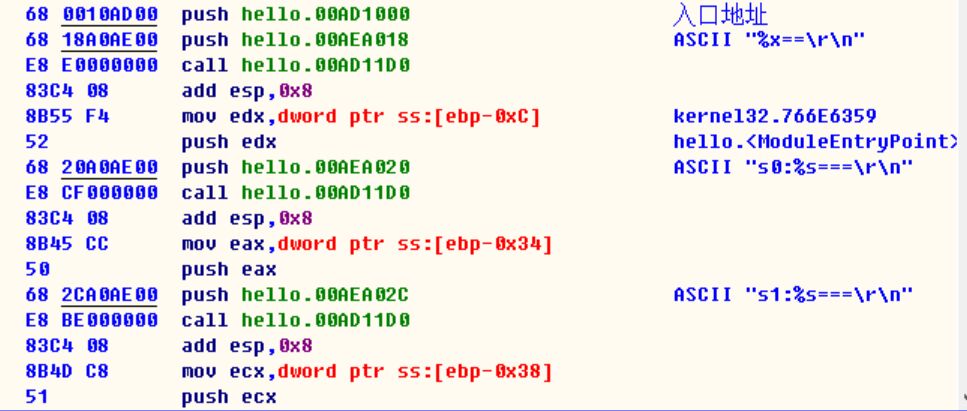
1)先把参数入栈(s0)
2) 第二步把对应的format地址入栈(“s0:%s====\r\n”)
3)调用printf函数
4)计算偏移地址,后面就看不懂了,肯定要把%s替换成对应的入参
5)类似printf的函数,这种入参数量不确定的
int test(int str_num, char *s_tmp, ...) {
char* p = NULL;
va_list s;
va_start(s, s_tmp);
printf("%s==\r\n", s_tmp);
for (int i = 0; i < str_num; i++)
{
p = va_arg(s, char*);
printf("%s==\r\n", p);
}
va_end(s);
return 0;
/*
像这种取入参个数不确定的,类似printf,其实在调用它的时候
fun里面有多少个参数,程序会在你调用之前把数据全部入栈
有多少个就入栈多少个,然后计算偏移地址,一个个去取
*/
}
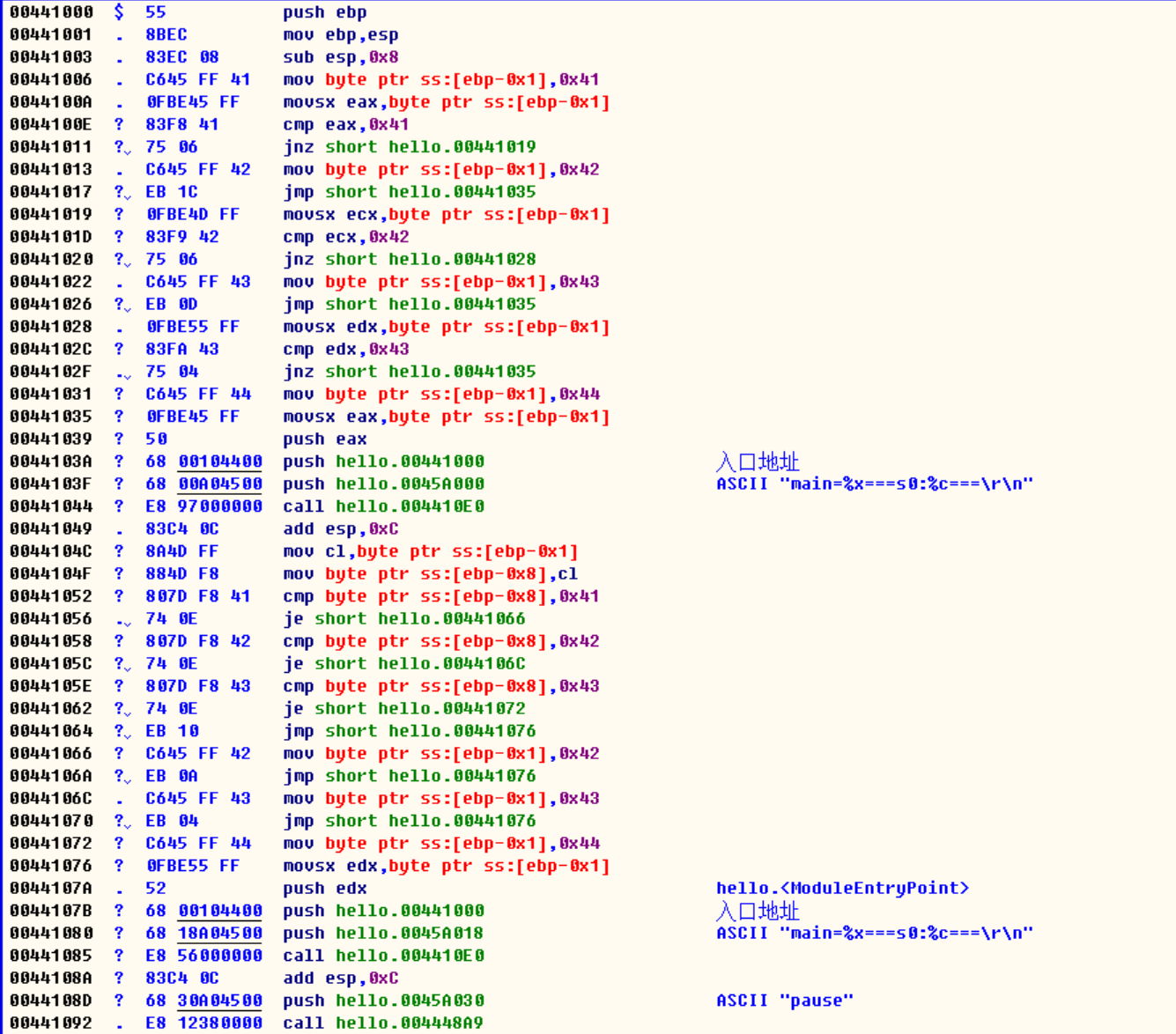
switch与if else
#include <stdio.h>
int main()
{
//字符请使用单引号,否则会被理解成字符串
char s0 = 'A';
if (s0 == 'A')
{
s0 = 'B';
}
else if (s0 == 'B')
{
s0 = 'C';
}
else if (s0 == 'C')
{
s0 = 'D';
}
printf("main=%x===s0:%c===\r\n", main, s0);
switch (s0)
{
case 'A':
s0 = 'B';
break;
case 'B':
s0 = 'C';
break;
case 'C':
s0 = 'D';
break;
default:
break;
}
printf("main=%x===s0:%c===\r\n", main, s0);
system("pause");
/*
对比switch 和 if else
1)仔细对比其实很多地方并没有多大区别
2)只是break直接回跳到switch的尾部
3)当然我觉得switch结构更清晰一点
4)如果可以用swich实现的,那就用switch,因为字符一匹配,程序是直接跳到结尾的
而if else 确还要一步步执行下去
*/
}
结构体和枚举
#include <stdio.h>
enum DAY
{
MON = 1,
TUE = 2,
WED = 3,
THU = 4,
FRI = 5,
SAT = 6,
SUN = 7,
UNKNOWN,
};
typedef struct {
int age;
char name[32];
char sex;
}Teacher;
typedef struct {
char sex;
int money;
char name[32];
char class[32];//班级名称
Teacher t;//学生对应的老师
}Student;
int main()
{
Student std;
std.t.age = 16;
std.sex = 1;
std.money = 16;
printf("main=%x===s0:%d===name:%s\r\n", main, UNKNOWN,std.name);
system("pause");
}
/*
1)在里面定义的结构体也是存储在栈里面
2)char sec 和 int money 距离了4个字节,在VS里面数据会以4字节对齐
那些空出的字节并没有被清零,在结构体里面没有初始化的数据都是随机的
3)没有发现枚举MON..什么的,编译成机器码后,枚举是自动翻译成了对应的数据
类似宏定义,那里用到哪里就替换
4)UNKNOWN直接被翻译成了0x8
5.字节对齐的好处?你可以从头到尾观察所有的定义内存块的汇编内存地址,都是偶数
why?简单来说,CPU读取数据是有限制的,一次只能读有限的字节,而且通过地址总线
是读取固定大小的内存块的数据,假设CPU一次读取8个字节,抱歉我要的是8到9
的内存单元你得读两遍,CPU说:你它妈的定义内存的时候,就不能直接从第9个开始吗,
一块内存居然要我搬两次,我选择自毁。
*/
全局变量和静态变量
#include <stdio.h>
typedef struct {
int age;
char name[32];
char sex;
}Teacher;
typedef struct {
char sex;
char name[32];
char class[32];//班级名称
Teacher t;//学生对应的老师
}Student;
Student std;
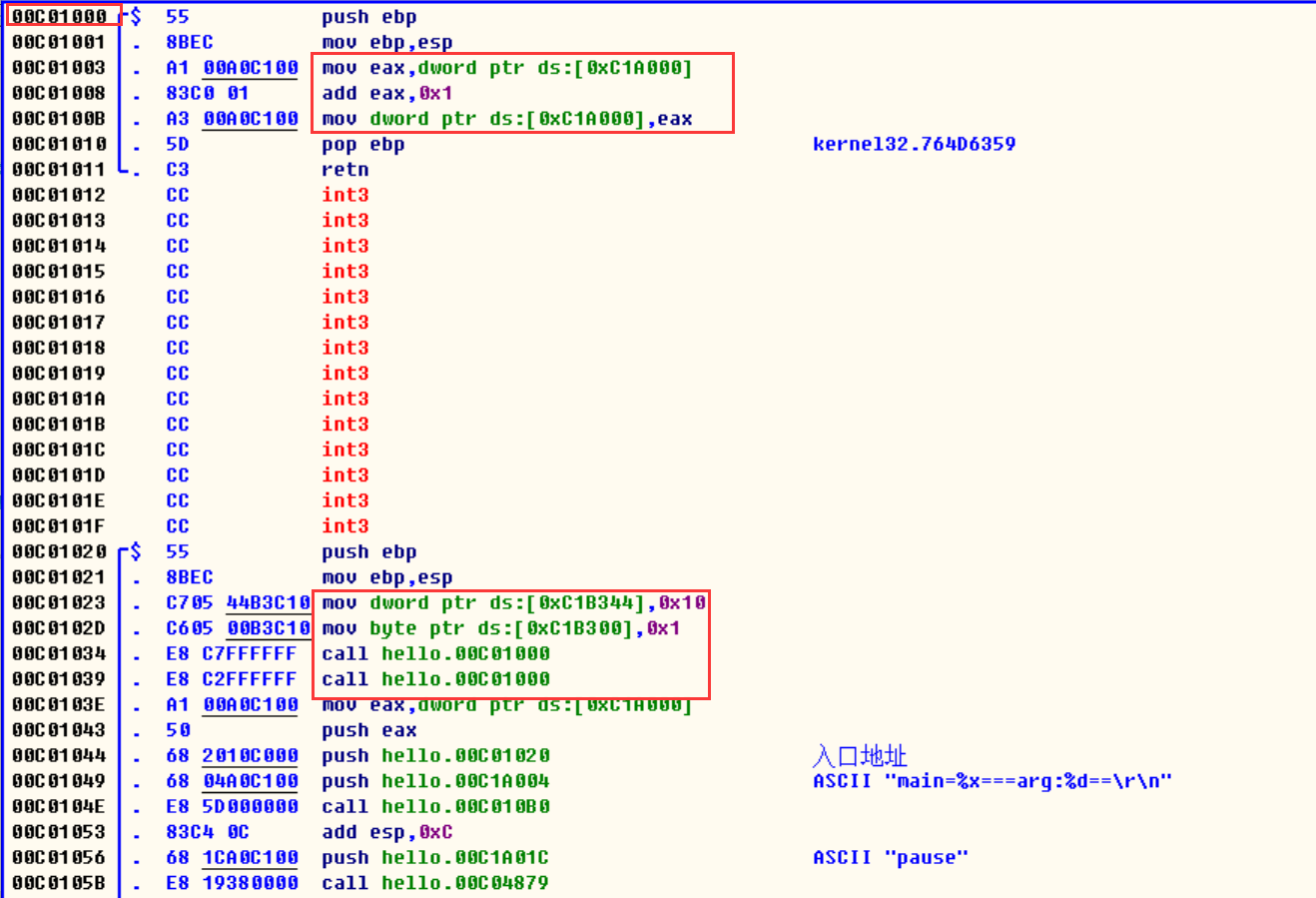
static int arg = 1;
void testStatic();
int main()
{
std.t.age = 16;
std.sex = 1;
testStatic();
testStatic();
printf("main=%x===arg:%d==\r\n", main, arg);
system("pause");
/*
1)定义的静态变量都存放在段内存里面,并不是存在栈里面的
2)定义的testStatic函数是放在在main函数之前.这也是
为什么函数要想写在main后面,就需要先声明才能在main函数里面使用
编译器需要通过你的声明找到函数地址
3)0x44 = 68,这里也可以看出字节对齐
*/
}
void testStatic()
{
arg += 1;
}
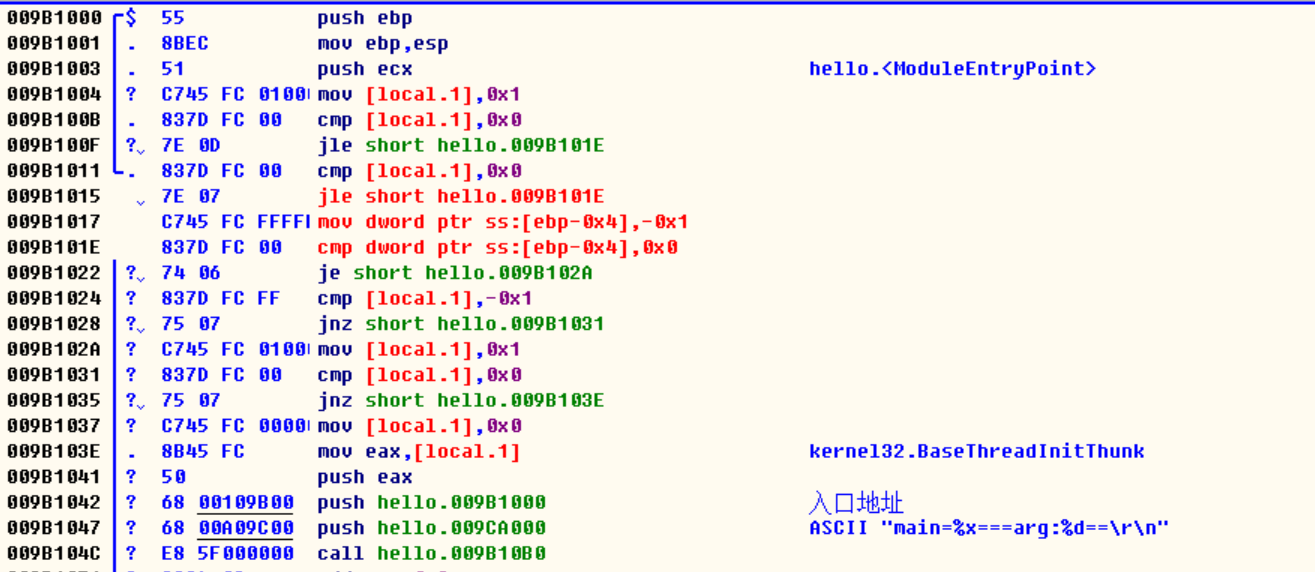
逻辑运算(多个条件的判断是如何实现的)
#include <stdio.h>
int main()
{
int arg = 1;
if (arg > 0 && arg > 0)
{
arg = -1;
}
if (arg == 0 || arg == -1)
{
arg = 1;
}
if (!arg) {
arg = NULL;
}
printf("main=%x===arg:%d==\r\n", main, arg);
system("pause");
/*
jle:如果小于就进行跳转
1)写两个相同的判断条件,编译器并不会进行优化
2)条件连用是编译器把一个条件拆分成两段代码来实现的
3)NULL 翻译成了0x0,因为宏定义里面NULL就是0
4)对与非命令(!)编译器用的是jnz(是否不为arg)
*/
}
i++与i–与for循环
#include <stdio.h>
int main()
{
int i = 0, num = 0;
int ary[8] = {0};
for (i = 10; i > 0; i--)
{
--i;
ary[num++] = 1;
ary[++num] = 0;
}
printf("main:%x==num:%d\r\n", main, num);
/*
1)ary[8] = {0} 8个单元的数据都会被清零
2)i--和--i本质无区别,在编里面都要执行--,
但是用在当数组下标的时候
ary[num++] 先执行的是ary[num],在执行num++
ary[++num] 先执行的是++num,再执行ary[num]
3)里面的for循环用的是jump和jle联合使用来完成的,跟8086还是有区别的
*/
}
多级指针
该程序仅仅用于测试,运行是会提示引用错误的内存空间的
#include <stdio.h>
int main()
{
int *a = 0, **b = 0, ***c = 0, ****d = 0;
*(a + 1) = 2;//指针加1,指针的地址加4,把2赋值到(a+4)这块地址
b = a;//通过寄存器间接给b地址赋值
*b = 1;//把b当作地址,给*b赋值为1
**b = 2;//把*b当作地址,给**b赋值为2
c = b;//通过寄存器间接给c地址赋值
**c = 1;//先找到*c为地址, **C 赋值为1
*c = 1;
c = b;
***d = 1;
**d = 1;
*d = 1;
d = c;
/*
1.定义多少个*号的初始变量,它们都是一样的赋值方式
2.它们的大小相同
3.一个多级指针有几个*号就有几个地址,也会有对应的值
它们的值比较奇妙,地址指向内存空间,内存空间又当作地址
4.多级指针可以一次传递多个参数
*/
}
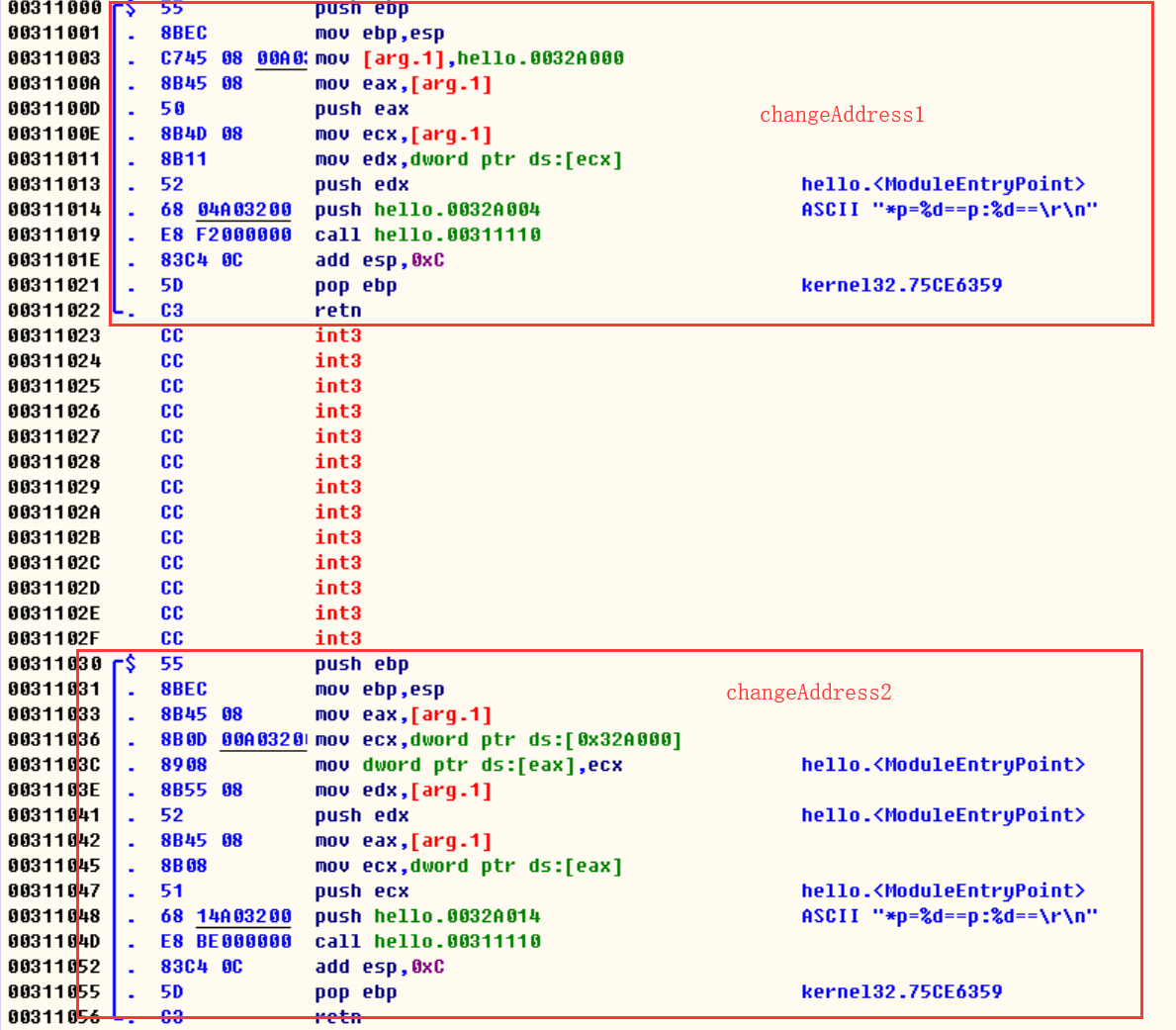
多级指针当作函数入参
#include <stdio.h>
int tmp = 16;
void changeAddress1(int *p)
{
p = &tmp;
printf("*p=%d==p:%d==\r\n", *p, p);
}
void changeAddress2(int **p)
{
*p = tmp;
printf("*p=%d==p:%d==\r\n", *p, p);
}
int main()
{
int a = 0;
printf("a:%d==\r\n", &a);
changeAddress1(&a);
printf("a:%c==\r\n", a);
changeAddress2(&a);
printf("a:%d==\r\n", a);
system("pause");
/*
1.说明上述两个函数:函数1没有改变a的值,函数2确实现了改变a的值
changeAddress1解说:
1)把tmp的地址赋值给了p,然后入栈
2)然后把p当作地址,把*p入栈
3)将p和*p压入栈里面调用printf函数
changeAddress2解说:
1)把入参移动到eax(eax是当作了目标地址),把tmp的值移动到a地址(eax)所指向的内存空间
2)然后把p当作地址,把*p入栈
3)将p和*p的值压入栈里面调用printf函数
首先:[arg.1]放的是传参的值
函数1:把a的地址拷贝给了p,然后修改了p的值,这样子它并没有改变a地址指向的内存空间
函数2:把a的地址拷贝给了p,然后把p当作地址,修改了p地址所指向的内存空间
这里注意函数的一点,函数入参
1)所有的入参都是拷贝,你可以拷贝值,也可以拷贝地址进来
2)&a与*p,它们两个完全不是一个东西,p是单独的一块空间,a也是单独一块的内存空间
3)写函数最大的误区就是,我可以改内存地址,千万不要犯这样的错。内存地址都是固定死的,
你只可以改变,地址所指向的内存空间,改的是内存的值,把0改成16
*/
}
C内存的释放
1.局部变量因为是存放在栈里面,所以函数执行完也就自然被释放掉了
2.静态变量和局部变量是如何释放的呢?
#include <stdio.h>
int a = 1;
int main()
{
static int b = 2;
b = a+b;
return b;
}
静态变量的位置就放在运行的程序的底部,并不在程序代码(代码区)里面
我编译了好几次,这个静态变量的位置和代码区的距离基本都是固定的
参考网络:
它本质上还是在程序里面的,系统加载程序是把程序分成不同的块处理的
静态变量位于静态区 ,静态区是跟随着程序结束,被系统一起释放的
3.malloc分配的内存是跟程序用的是一块内存吗?
#include <stdio.h>
int main()
{
char *p = malloc(sizeof(char)*10);
printf("%s==\r\n", *p);
free(p);
return;
}
分配给p的地址(eax是00D3FA68),基本上我每编一次地址都是发生不同的变化
分配的地址我是没有找到规律,有时在代码段的前面,有时在后面, 相对静态区距离更远
而且分配的内存是没有被清零的,都是随机值
参考网络:
它分配的内存并不在程序内存里面, 在系统内存的其它地方,malloc是系统接口
分配的内存如果我们不调用free函数释放的话,程序结束是不会释放的
这块malloc内存通常会交给系统回收,系统释放通常都是很慢的,耗性能的
malloc很容易造成内存碎片,因为分配的内存块都是随机不规律的
尽量分配内存空间提前定义一个数组,这样速度快,避免内存泄露
少使用malloc
汇编与JAVA
类与main函数的执行过程
//HelloWorld.java
public class HelloWorld {
public static void main(String[] args){
System.out.println("Hello World!");
}
}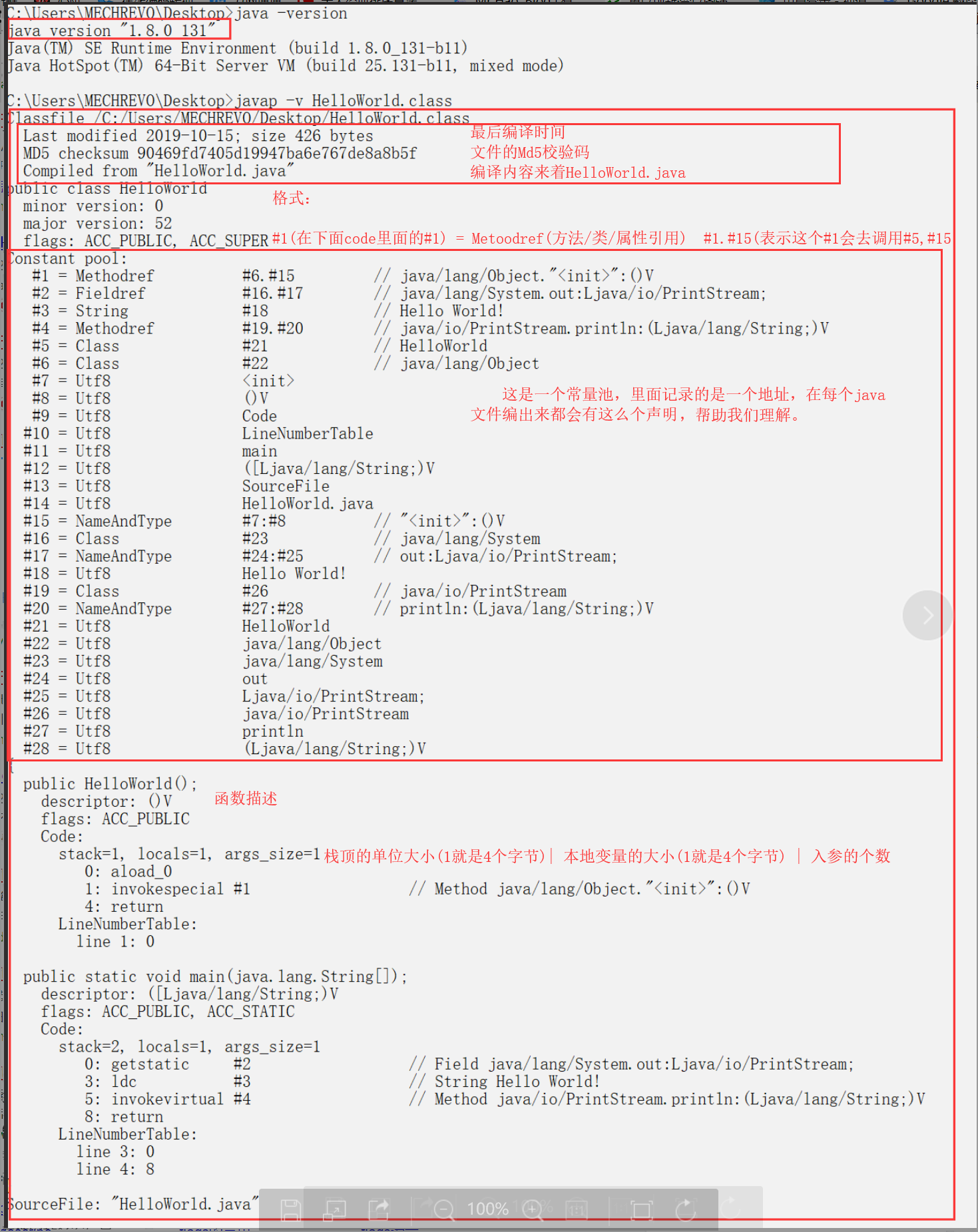
我的测试环境是1.8版本的java环境,所有的代码均由javap -c指令在cmd直接生成
JVM字节码参考均来自: https://segmentfault.com/a/1190000008722128
JVM的虚拟机参考均来自: https://www.jianshu.com/p/26f95965320e
文章里面为了简短一点,尽量使用javap -c,
局部变量表(LocalVariableTable)和代码关系表(LineNumberTable)自动忽略了
局部变量表(在java文件里面使用了变量,就会有这么一个东西,在文件尾部)
使用javap -v/ javap -g编译
LocalVariableTable:
Start Length Slot Name Signature
0 133 0 this Lcom/my/class/Test;
2 131 1 a I
4 129 2 b I
7 126 3 i I
10 123 4 i2 I
16 117 5 o1 Ljava/lang/Integer;
31 102 6 o2 Ljava/lang/Integer;
局部变量表:
变量的开始偏移位置|变量的作用域/长度|第几个存储单元|变量名称|类型标识符
0 133 0 this Test
这个局部变量表里面记录了变量与内存的关系,调试的时候就需要这个表 因为java编译出的字节码是交给java虚拟机进行处理的(我没法无法翻译成机器码)
反编译出来的结果就相当于一套新的CPU处理指令
javap编译出来的字节码文件看起来倒是比机器码好看多了
它的code里面是这样子的
Code:
stack=2, locals=1, args_size=1
0: getstatic #2 // Field java/lang/System.out:Ljava/io/PrintStream;
3: ldc #3 // String Hello World!
5: invokevirtual #4 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
8: return
声明下面是一段代码:
栈的大小, 局部变量的大小, 入参的个数
0(开始地址): 子函数 #1(父函数)
3(开始地址): 子函数 #3(父函数)
8(开始地址): 函数
从开始地址和下一个开始地址,是可以计算出这一条指令要多少个地址的
例如0,它下一个偏移地址是3
也就是说0地址的机器码是占用了3个字节的(0,1,2)
从图片可以发现java执行类的时候,第一步调用类的构造方法,第二步再调用main函数
为什么要先调用构造方法,而不直接调用main函数呢?
java诞生于1995年,C++诞生于1983年。早在C++的时候就提出了面向对象编程。简单来说就是把一个main函数拆分成好几个函数,公用函数反复起来用。其实我感觉现在的面向对象都是虚假的面向对象,它本质上还是处于一个低级阶段,真正的面向对象应该是巨大完善的对象库,由全世界的程序员共同补全信息, 我一点也不想去写一些重复的代码和方法。
把main函数里面的方法抽出来的好处, 增强了一点点代码的复用性和理解性, 这样以类的形式划分代码好处就是明确把代码的结构体和函数功能划分出来。面向对象告诫我们程序员写代码不要直接从main函数就写下去了,先得考虑程序的扩展性和内存分配的问题, 先出设计,再码代码。
这就是为了体现面向对象的编程思想,先把整个程序结构想好,再给你执行代码。
java 8种基本类型的强转
public class HelloWorld {
public static void main() {
boolean f = false;//4个字节
byte a = 1;//4个字节
char b = 2;//4个字节
short c = 3;//4个字节
float d = 4;//4个字节
double e = 5;//8个字节
int g = 6;//4个字节
long h = 7;//8个字节
a = (byte) b;
b = (char) c;
c = (short) d;
d = (float) e;
e = g;
g = (int) h;
//boolean不支持其它7种类型的强转
//iconst_数字 把数字压栈
//istore_地址 把上个一压栈的的值赋值给 地址
}
}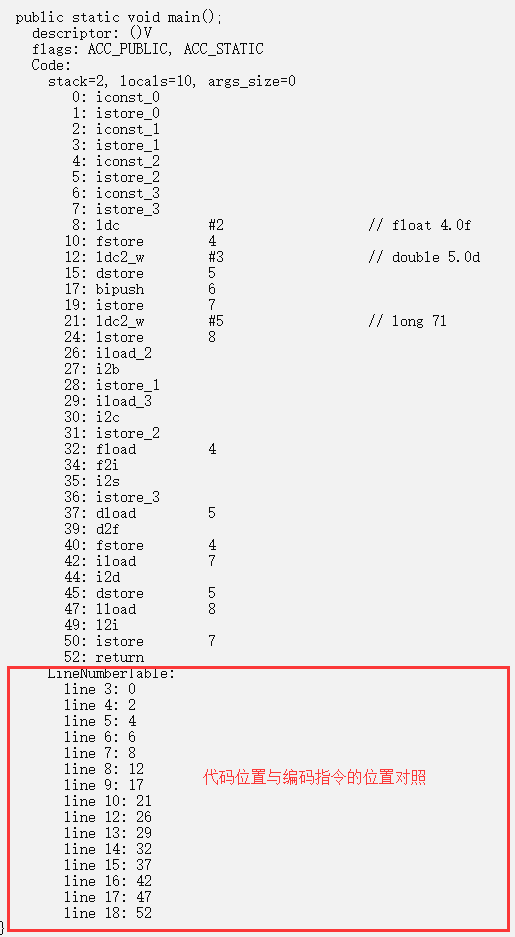
1.stack 共8个字节, 本地变量40个字节, 入参0字节
2.通过字节码发现, 我们定义的类型编译器并没有做什么排序,按照原顺序生成字节码
在C里面编译器是会自动优化排序节省字节的并且对齐,观察生成的机器码
定义的boolean, byte,char, short居然用的都是同一个命令
istore和iconst,这两个都是操作Int型数据的, 也就是说很有可能java实现4字节对齐
那就是向上对齐,不足4字节用0补全,不做内存优化。
3.iload(把一个int型数据送入栈顶), i2c(把栈顶的的int型数值转换成char压入栈顶)
所有的强转都有对应的机器码, 它们转换步骤基本都是(出栈, 转换, 赋值)
4.float转short步骤
fload(float变量出栈) => f2i(float转int) => i2s(int转short) => istore(赋值)
JAVA 4种访问修饰符
public class HelloWorld {
public int a = 0;
private int b = 1;
protected int c = 2;
int d = 3;
public static void main() {
HelloWorld h = new HelloWorld();
h.a = 0;
h.b = 1;
h.c = 2;
h.d = 3;
}
//从字节码上,好像没什么区别
//我一直很好奇怎么控制结构体里面的访问权限(整这个东西是为了加密吗?)
//java字节码可以被反编译,权限不是那种查看权限,这个权限指的是改变值的权限
//原来这是编译器来实现的,并不是通过代码实现
//使用外部包访问,编译器直接提示访问不了,编译错误,权限这东西原来是编译器控制的
}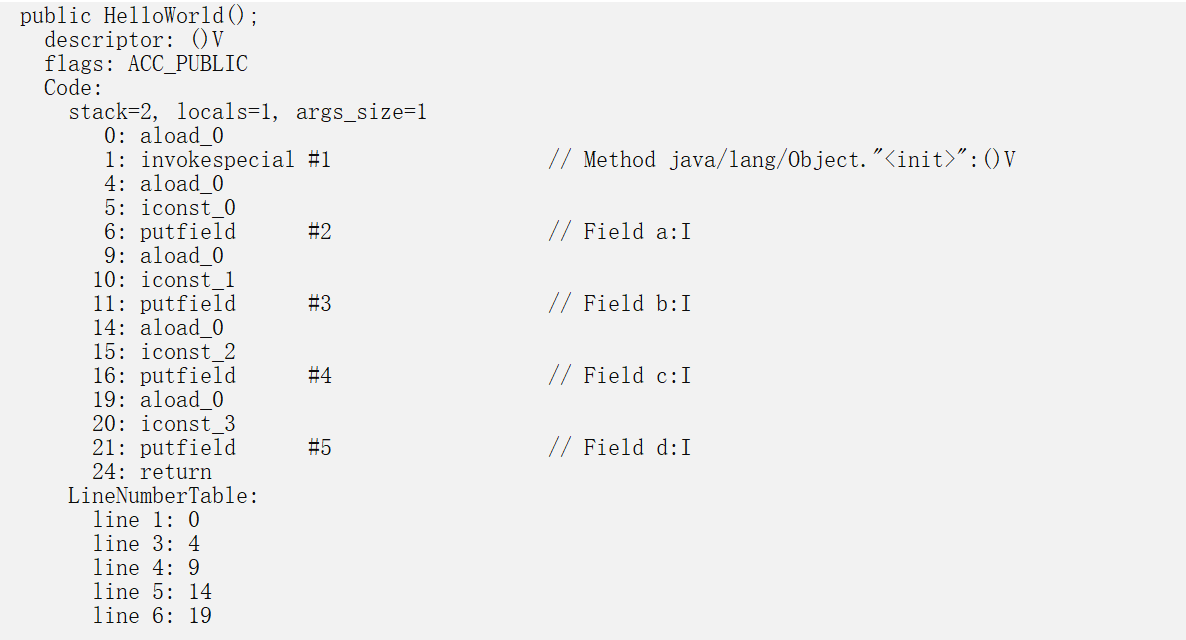
访问权限 类 包 子类 其他包
public ∨ ∨ ∨ ∨ (对任何人都是可用的)
private ∨ × × × (除类型创建者和类型的内部方法之外的任何人都不能访问的元素)
protect ∨ ∨ ∨ × (继承的类可以访问以及和private一样的权限)
default ∨ ∨ × × (包访问权限,即在整个包内均可被访问)
java类的抽象与继承
public abstract class Employee { //父类,描述雇员共有信息(抽象类)
private String name;
public Employee(){}
public Employee(String name) {
this.name=name;
}
public String getName() {
return name;
}
public abstract double ComputeSalary() ; //抽象方法,计算雇员的工资,子类要重写
}
class Manager extends Employee{ //Manager类,计算经理工资
private double monthwage; //经理固定月工资
public Manager() {}
public Manager(String name,double monthwage) {
super(name);
this.monthwage=monthwage;
}
public double ComputeSalary() {
return monthwage;
}
}
class Salesman extends Employee{ //计算销售人员工资
private double baseSalary; //基本工资
private double commision; //销售每件的提成
private int qualtities; //销售件数
public Salesman() {}
public Salesman(String name,double baseSalary,double commission,int qualitities) {
super(name);
this.baseSalary=baseSalary;
this.commision=commission;
this.qualtities=qualitities;
}
public double ComputeSalary() {
return baseSalary+commision*qualtities;
}
}
class Worker extends Employee{ //计算一般工人工资
private double dailySalary; //每天工资
private int days; //每月工作天数
public Worker() {}
public Worker(String name,double dailySalary,int days) {
super(name);
this.dailySalary=dailySalary;
this.days=days;
}
public double ComputeSalary() {
return dailySalary*days;
}
}public class Employees {
public static void main(String aegs[]) {
Manager manager_1=new Manager("张三",6000);
Salesman salesman_1=new Salesman("李四",2500,30,90);
Worker worker_1=new Worker("王五",200,24);
System.out.println("张三这个月的工资为"+manager_1.ComputeSalary()+"元");
System.out.println("李四这个月的工资为"+salesman_1.ComputeSalary()+"元");
System.out.println("王五这个月的工资为"+worker_1.ComputeSalary()+"元");
}
}
在myeclipse2019里面我写了两个类, myeclipse自动帮我们把一个java文件里面的类全都给抽出来了
这编译器是真的6,如果直接javac, employees会提示找不到类的,
大家写类的时候要注意一个类写一个文件,多个类写在一个文件。
如果编译器不智能的话肯能会提示报错的。
抽象类Employees

子类Worker

main类Employees

什么是抽象类和抽象方法?
1.抽象类和普通的类并没有多大的区别, 只是里面有抽象方法就得是个抽象类
这东西就是满足结构体和方法的扩展性,少写代码,增加规范
2.抽象方法就是编译器告诉你,你继承了父类,这个父类方法必须实现,不然编译器不通过
3.抽象类是New不出来的
什么是继承?
1.继承就是,类初始化的时候先调用下父类的构造方法,在子类用到
父类的变量时候,先把变量传入父类,父类先过一遍函数,子类再处理
java接口和类
interface eat{
void dinner();
}
interface sleep{
void doze();
}
public class Employees implements eat, sleep {
public void dinner() {
// TODO Auto-generated method stub
int a = 0;
}
public void doze() {
// TODO Auto-generated method stub
int a = 0;
}
public void money() {
int a = 0;
}
}
//我使用myeclipse编译出来发现每一个接口都会生成一个class文件
//interface eat 自动生成了eat.class
//interface sleep自动生成了sleep.class
//所谓的接口其实也是编译器搞出来的东西,你不实现就不让你运行
//1.在实现接口方法的时候,这些实现方法并没有调用eat的构造方法,只是单纯的普通函数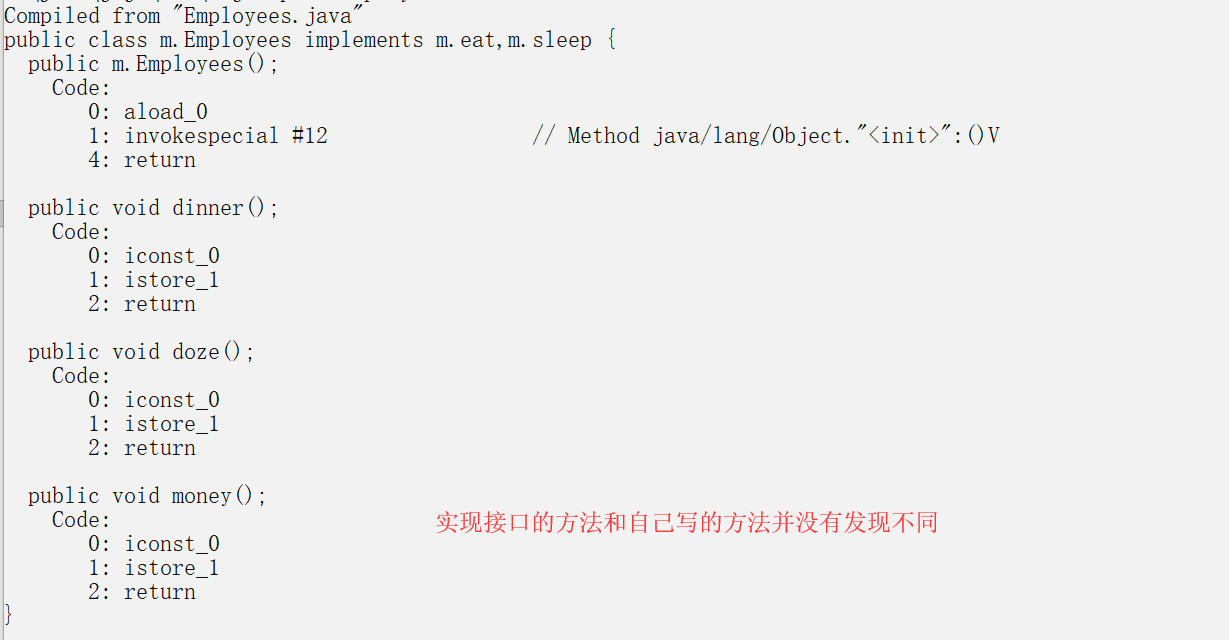
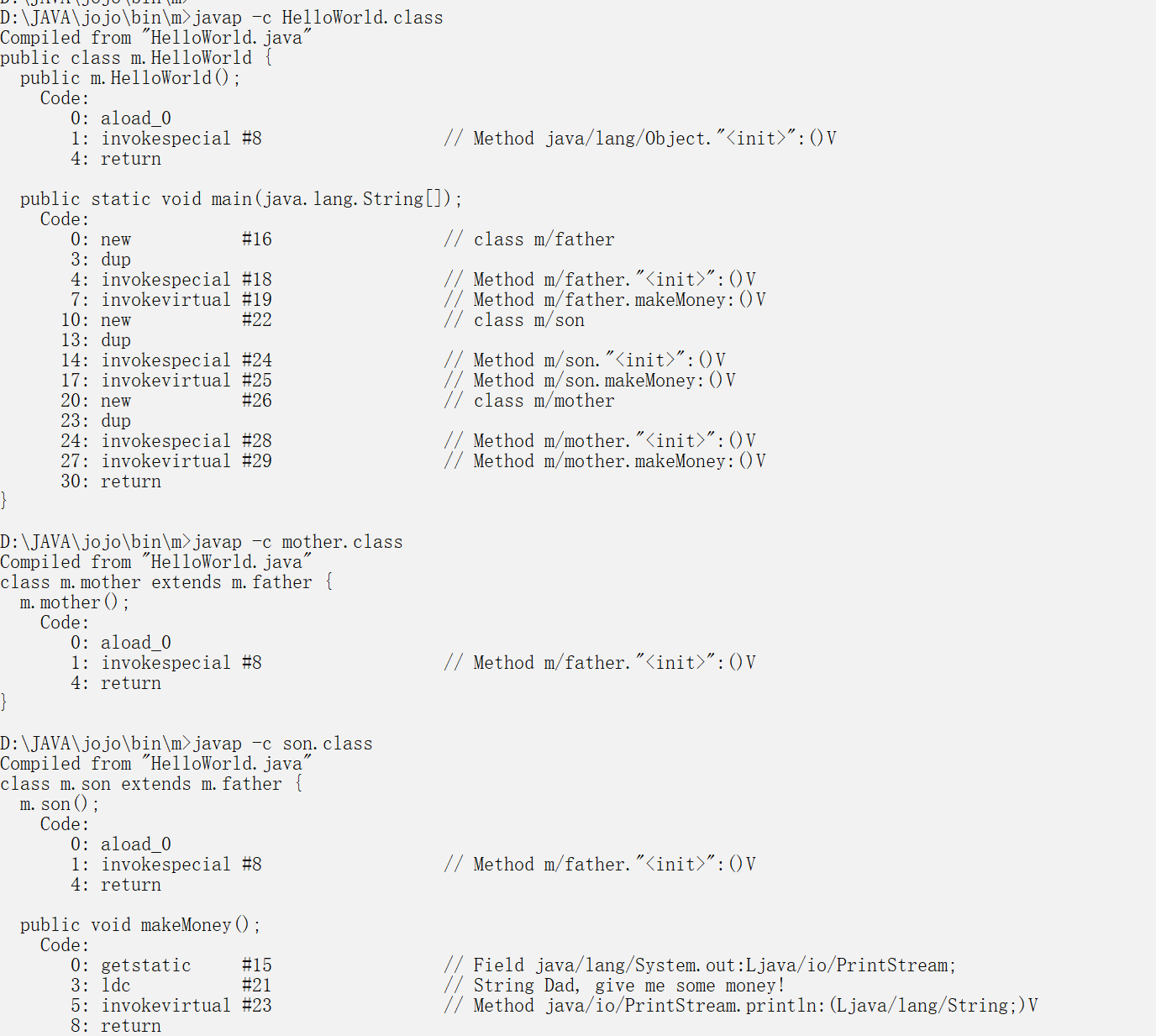
类方法的重写
//类方法的重写
class father{
public void makeMoney()
{
System.out.println("For the son of trash!");
}
}
class son extends father{
public void makeMoney()
{
System.out.println("Dad, give me some money!");
}
}
class mother extends father{
}
public class HelloWorld {
public static void main(String[] arg)
{
new father().makeMoney();
new son().makeMoney();//son类执行的是自己的makeMoney方法
new mother().makeMoney();//mother类执行的是father的makemoney方法
}
//单单从编译结果看
//重写只不过是把父类的函数覆盖了而已
//在new son类的时候,先执行父类的初始化方法,然后再执行子类的方法
//执行子类初始化的时候,子类的方法把父类的方法给覆盖掉
//其实mother和son执行的都是父类的方法,只不过son重写,把父类的方法覆盖了
}
函数的重载
public class HelloWorld {
public int init() {
return 0;
}
public String init(int a) {
return "";
}
public String init(int a, int b)
{
return "";
}
public static void main(String[] arg)
{
new HelloWorld().init();
new HelloWorld().init(1);
new HelloWorld().init(1,1);
//java实现的函数重载,会给重载的函数都加上标识符
//编译器通过标识符去识别该使用哪个重载函数
}
}
多态(父类定义子类的好处)
1.子类继承于父类。子类和父类的结构,基本上它们的前面一截内存都会是同样的结构
2.继承过来的参数,函数地址会一一对照,这样的好处就是少写了很多代码,代码更加的抽象
3.但是如果子类也是有自己的方法的和参数,子类和父类的结构体后半部分会产生差异。
也就是说,父类定义的子类,子类的非继承方法是找不到的。因为父类的结构体是不包含
子类的私有方法和属性的。但是子类new出来的一瞬间,它的内存结构已经分配好了,可以通过
强转(告诉编译器,实际上这个结构体有这么大)把子类的私有方法给找回来。
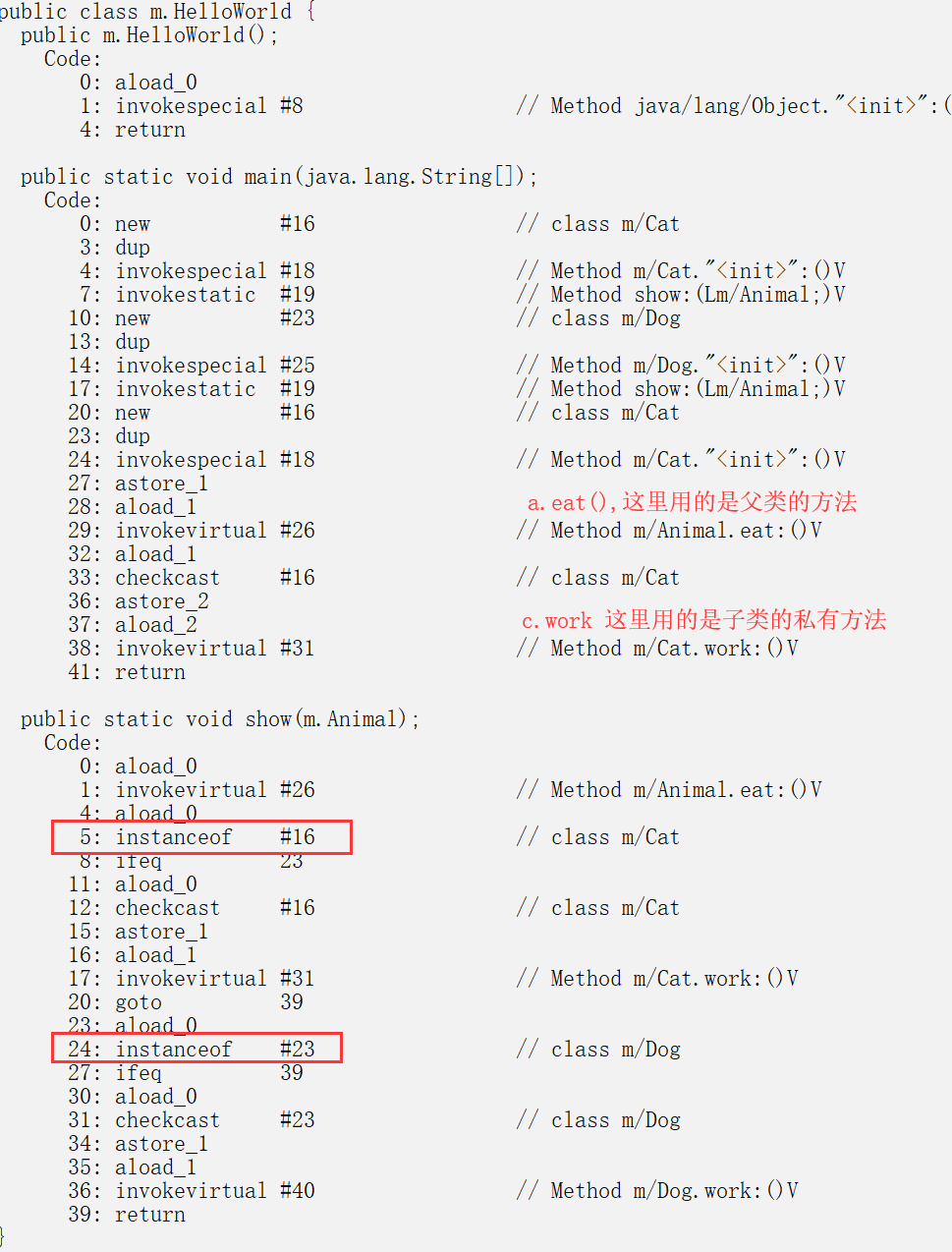
public class HelloWorld {
public static void main(String[] args) {
show(new Cat()); // 以 Cat 对象调用 show 方法
show(new Dog()); // 以 Dog 对象调用 show 方法
Animal a = new Cat(); // 向上转型, 后果就是子类的私有方法和属性会丢失
a.eat(); // 调用的是 Cat 的 eat
//a.work 会提示找不到这个方法,因为它进行了向上转型,丢失了自己的属性
Cat c = (Cat)a; // 向下转型,保留了自己的属性
c.work(); // 调用的是 Cat 的 work
}
public static void show(Animal a) {
a.eat();
// 类型判断
if (a instanceof Cat) { // 猫做的事情
Cat c = (Cat)a; //强转把子类的私有方法(地址)找回来
c.work();
} else if (a instanceof Dog) { // 狗做的事情
Dog c = (Dog)a;
c.work();
}
}
//这样以结构体的形式去校验对象,用起来非常灵活
//智能检测类型,switch(类型)然后执行对应方法, 6的飞起
}
abstract class Animal {
abstract void eat();
}
class Cat extends Animal {
public void eat() {
System.out.println("吃鱼");
}
public void work() {
System.out.println("抓老鼠");
}
}
class Dog extends Animal {
public void eat() {
System.out.println("吃骨头");
}
public void work() {
System.out.println("看家");
}
}
枚举类
//在C里面的枚举只不过相当于一个宏替换而已
//在java里面枚举是被视为一个类的,枚举是为了更清晰的表达代码
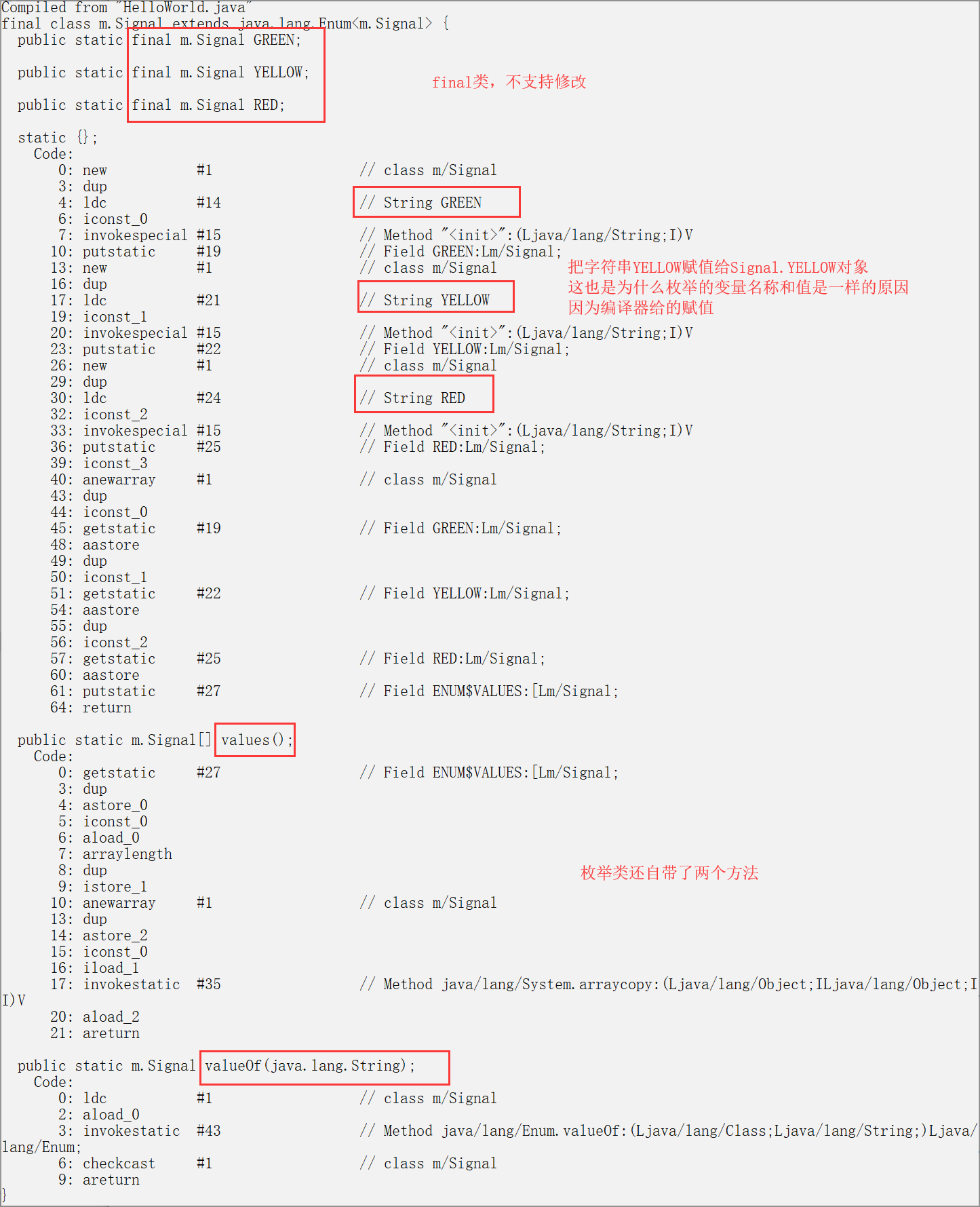
枚举类的特殊性,枚举也是定义的枚举对象是不能修改的,
因为枚举默认都是final修饰,枚举不支持继承,派生子类
枚举类是一个静态类,属性都是static final, 提供的方法也都是静态的
枚举类的代码虽然简短,但是机器码实现却是非常多的,比C的复杂很多
enum Signal {
GREEN, YELLOW, RED, 1
} 
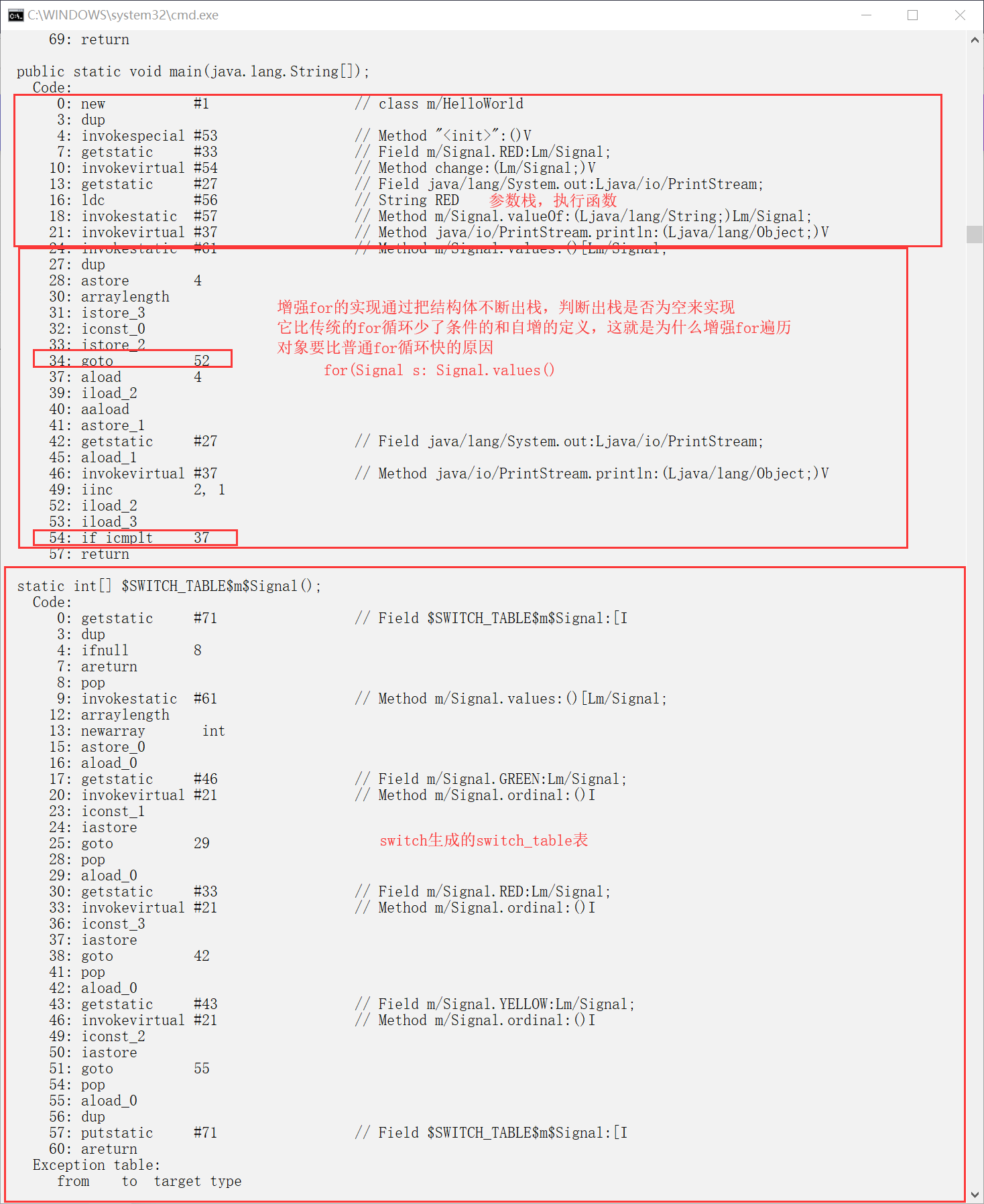
//枚举类引用是如何实现的
public class HelloWorld {
public void change(Signal color) {
switch (color) {
case RED:
System.out.println(Signal.RED);
break;
case YELLOW:
System.out.println(Signal.YELLOW);
break;
case GREEN:
System.out.println(Signal.GREEN);
break;
}
}
public static void main(String[] arg)
{
new HelloWorld().change(Signal.RED);
for(Signal s: Signal.values())
{
System.out.println(s);
}
System.out.println(Signal.valueOf("RED"));
}
}
使用枚举定义方法和变量
//枚举居然不能RED = 1这么写, 那么枚举只能是字符串吗?
//要知道枚举也是一个类,是可以实现字符串绑定对应的数字,这好麻烦啊
//但是它还可以提供枚举对象的父类方法重写,这就牛逼了,只要在枚举
//对象后面加个{重写父类方法},有点类嵌套类的感觉,它这样的写法缩短了
//非常多的代码,但是编译器确要干很多活的。
//重写一个父类方法,编译器就会给你生成一个匿名类来实现重写。
//也就新生成了一个结构体对象。其实枚举的实现很机器,单纯就是为了程序员少写代码
//后果就是代码更抽象了,毕竟这样的写法只有java才有
enum Signal {
RED{
public String getChar() {//重写父类的方法
return "I AM RED";
}
},
YELLOW(1,"YELLOW"){
public String getChar() {
return "I AM YELLOW";
}
},
GREEN(0){
public String getChar() {
return "I AM GREEN";
}
};
private int num;
private String str;
private Signal(){}
private Signal(int num){
this.num = num;
}
private Signal(int num, String str){
this.num = num;
this.str = str;
}
public String getStr() {
return this.str;
}
public int getNum() {
return this.num;
}
public String getChar() {
return this.getChar();
}
}
public class HelloWorld {
public static void main(String[] arg)
{
for(Signal s: Signal.values())
{
System.out.println(s+"==="+s.getStr()+"==="+s.getNum()+"=="+s.getChar());
}
}
}
//打印结果
//RED===null===0==I AM RED
//YELLOW===YELLOW===1==I AM YELLOW
//GREEN===null===0==I AM GREEN
RED(0) => 编译器会要求你提供 Signal(int num)的构造方法
通常这样写作用就是把RED对象的0给你存到RED结构体里面去
哈希表
(key-value)这种数据结构类似数组结构,但是又有链表的优点
真实情况是它的速度比数组查找慢,比链表增删慢, 因为
Hash 查找删除对象需要把key给转成下标,保证唯一性,计算内存空间够不够
但是它实现了这么强大的功能,牺牲这么一点计算性能是完全划算的
在java的JDK里面提供了最常用的两个Table(HashTable和HashMap)类
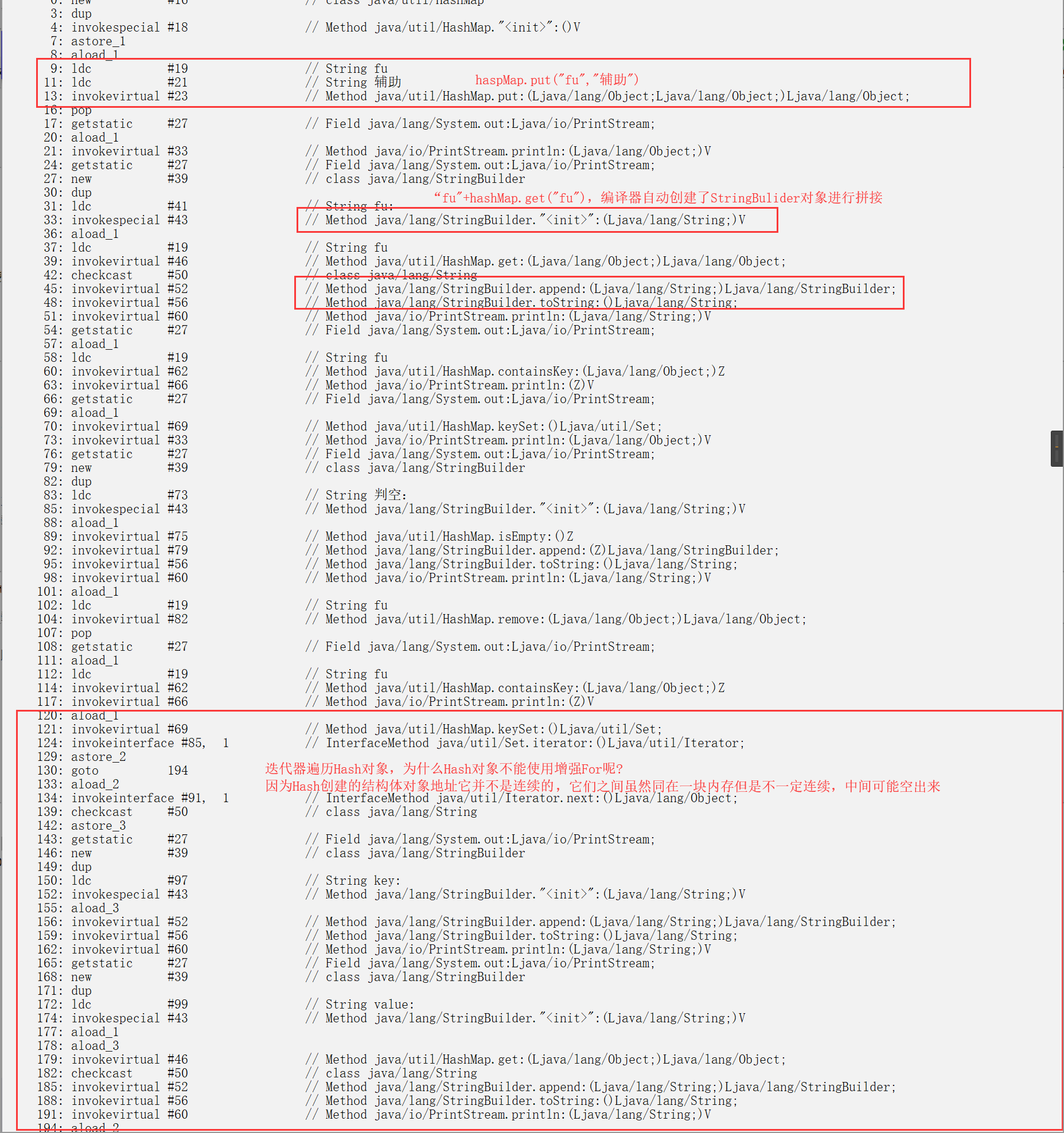
import java.util.HashMap;
import java.util.Iterator;
public class HelloWorld {
public static void main(String[] args) {
HashMap<String, String> hashMap = new HashMap<String, String>();
hashMap.put("fu", "辅助");
System.out.println(hashMap);//toString重写了,所以可直接打出
System.out.println("fu:" + hashMap.get("fu"));//拿出key为fu的键值
System.out.println(hashMap.containsKey("fu"));//判断是否存在fu的键
System.out.println(hashMap.keySet());//返回一个key集合。
System.out.println("判空:"+hashMap.isEmpty());//判空
hashMap.remove("fu");
System.out.println(hashMap.containsKey("fu"));//判断是否存在fu的键
Iterator it = hashMap.keySet().iterator();//遍历输出值。前提先拿到一个装载了key的Set集合
while(it.hasNext()) {
String key = (String)it.next();
System.out.println("key:" + key);
System.out.println("value:" + hashMap.get(key));
}
}
//在HashMap.Class里面 get() => getEntry方法, 你可以看到HashMap结构是一个数组
//getEntry就是通过table[indexFor(hash, table.length)]拿到对象的
//key被hash()转换成了int, 然后算出对象的大概位置,把值给取出来
}
//HashTable和HashMap javap编出来的差不多,只是调用不同的类而已
//HashMap支持key是null
//但是HashTable和HashMap在代码上几乎是99%不相同,(1%作者,包,io类引用,Cloneable)
//Hashtable几乎遍地都是Synchronized,是个方法就加锁
//在HashTable.class文件里面有这么句话
//如果需要高度并行的实现,然后推荐java.util.concurrent.ConcurrentHashMap
//难道Hashtable给每个函数都加锁还不够高度并行吗?
//参考网络:
//ConcurrentHashMap从锁函数升级到了锁内存块(Map分为N个Segment),好处就是细化到
//了内存块,这个块内存volatile说没有线程在用, 就不用等待了。而Hashtable的内存块是一整块的,一块
//内存不能用(也就是函数阻塞了),整个内存块都不能用了,别的线程给我等。
//ConcurrentHashMap就这样提升了多线程访问内存的效率
//看上去Hashtable好像弱爆了,实际上是ConcurrentHashMap这个东西太笨重了(用于超多线程)
//ConcurrentHashMap把内存块进行了分段,它增加了一个操作,寻找在哪个段,而且段还加锁
//Hashtable用于少量的线程增删操作,ConcurrentHashMap适合线程偏多且增删多
//Hashtbale和ConcurrentHashMap是要根据不同的场景来用的
import java.util.Hashtable;
import java.util.Iterator;
public class HelloWorld {
public static void main(String[] args) {
Hashtable<String, String> hashTable = new Hashtable<String, String>();
hashTable.put("fu", "辅助");
hashTable.put("ad", "输出");
hashTable.put("sd", "上单");
System.out.println(hashTable);//toString重写了,所以可直接打出
System.out.println("fu:" + hashTable.get("fu"));//拿出key为fu的键值
System.out.println(hashTable.containsKey("fu"));//判断是否存在fu的键
System.out.println(hashTable.keySet());//返回一个key集合。
System.out.println("判空:"+hashTable.isEmpty());//判空
System.out.println(hashTable.containsKey("fu"));//判断是否存在fu的键
Iterator it = hashTable.keySet().iterator();//遍历输出值。前提先拿到一个装载了key的Set集合
while(it.hasNext()) {
String key = (String)it.next();
System.out.println(it.next());
System.out.println("value:" + hashTable.get(key));
}
}
}模拟HashMap引发死循环
//测试案例借鉴:https://www.cnblogs.com/xrq730/p/5037299.html
//多线程不安全的知识:http://xxgblog.com/2013/05/16/java-thread-safe/
//酷壳(HashMap的死循环):https://coolshell.cn/articles/9606.html
import java.util.HashMap;
import java.util.Map;
import java.util.concurrent.atomic.AtomicInteger;
public class HashMapThread extends Thread
{
private static AtomicInteger ai = new AtomicInteger(0);
private static Map<Integer, Integer> map = new HashMap<Integer, Integer>(1);
public void run()
{
while (ai.get() < 100000)
{
map.put(ai.get(), ai.get());
ai.incrementAndGet();
}
}
public static void main(String[] args)
{
HashMapThread hmt0 = new HashMapThread();
HashMapThread hmt1 = new HashMapThread();
HashMapThread hmt2 = new HashMapThread();
HashMapThread hmt3 = new HashMapThread();
HashMapThread hmt4 = new HashMapThread();
hmt0.start();
hmt1.start();
hmt2.start();
hmt3.start();
hmt4.start();
//运行该方法会发生三种情况
//第一种:程序正常结束
//第二种: 提示数组下标越界(线程1正在扩容,已经确定好了table长度,
//但是内存还没有new 出来, 线程2要求使用未new 出来的内存)
//第三种: 程序一直不结束也不报错(内部发生了死循环)
}
}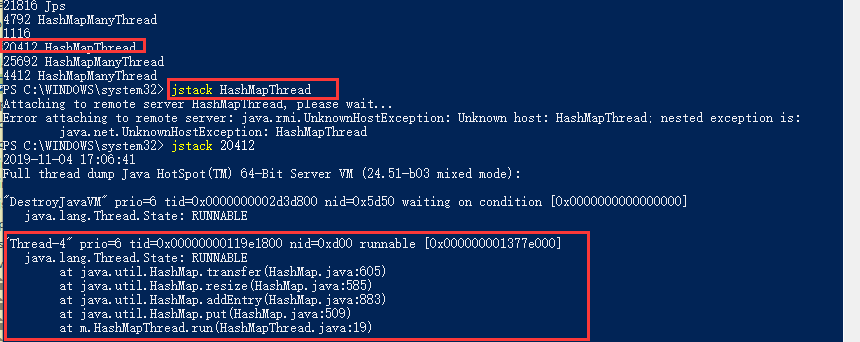
如图看到Thread4引发的HashMap扩容引发的死循环,定位函数transfer(数据迁移函数)
//1.7.0_51的源码
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);//释放旧Entry数组的对象引用(for循环后,旧的Entry数组不再引用任何对象)
}
int i = indexFor(e.hash, newCapacity);//重新计算每个元素在数组中的位置
//将当前entry的next链指向新的索引位置,newTable[i]有可能为空,有可能也是个entry链,如果是entry链,直接在链表头部插入。
e.next = newTable[i];//标记下一个位置
newTable[i] = e;//将元素放在数组的头部
e = next;//访问下一个Entry链上的元素,605行,next永远不会是null,程序卡死在这里了
}
}
} hashMap达到一定的容量的时候就会自动扩容,扩容那就要创建新数组,进行数据地址迁移
理解为什么会死机,就要理解Hash要扩容时候的状态
扩容时候的状态: 一个数组的单位绑定了多个Entry对象,这个时候对于遍历Hash效率就要慢下来了
效率慢的原因:因为它现在直接得到了数组下标对应的对象,还要去遍历下链表,要遍历两个对象
HashMap发现这样不行,一个数组单位只能绑定少量的Entry对象,要不然Hash的查找效率就不高了
重点:扩容那就要重新计算Entry跟数组单位的绑定关系,最好是一个Entry对应一个数组单位
要实现一个Entry一个数组对象,原来的链表的关系就要解绑,多线程去实现这个链表关系解绑,问题就出来了
原来的没有扩容的结构:[0] -> A -> B -> C -> null,假设数组长度为2
扩容数组长度变为4,后根据indexFor的算法,头插法
最终结果[0]->C->NULL, [2] -> B-> A -> NULL
线程1: A->B,中断,挂起
线程2: 我已经运行完了,B->A
线程1: (汇编角度:把数据还原到原来函数),找B->next的时候, B->next怎么是A了,死循环了
在JDK1.8里面就改成插入尾部了,可以明显看到e.next = null,这样子怎么都不会死循环了泛型(Generics)
1.泛型其实就是在定义类、接口、方法的时候不局限地指定某一种特定类型,而让类、接口、方法的调用者来决定具体使用哪一种类型的参数。
2.直白的说这是一种编译器的规范,编译器就是要求这么写的,声明了它是什么类型,编译器就只认这个类型
3.泛型的实现本质靠的都是Object,看到什么T,V,K,E,?通通想象成Object就是了,只不过编译器会判断这个Object是不是和你写声明的类型是不是一致的
import java.util.ArrayList;
import java.util.List;
public class HelloWorld{
public static void main(String[] args) {
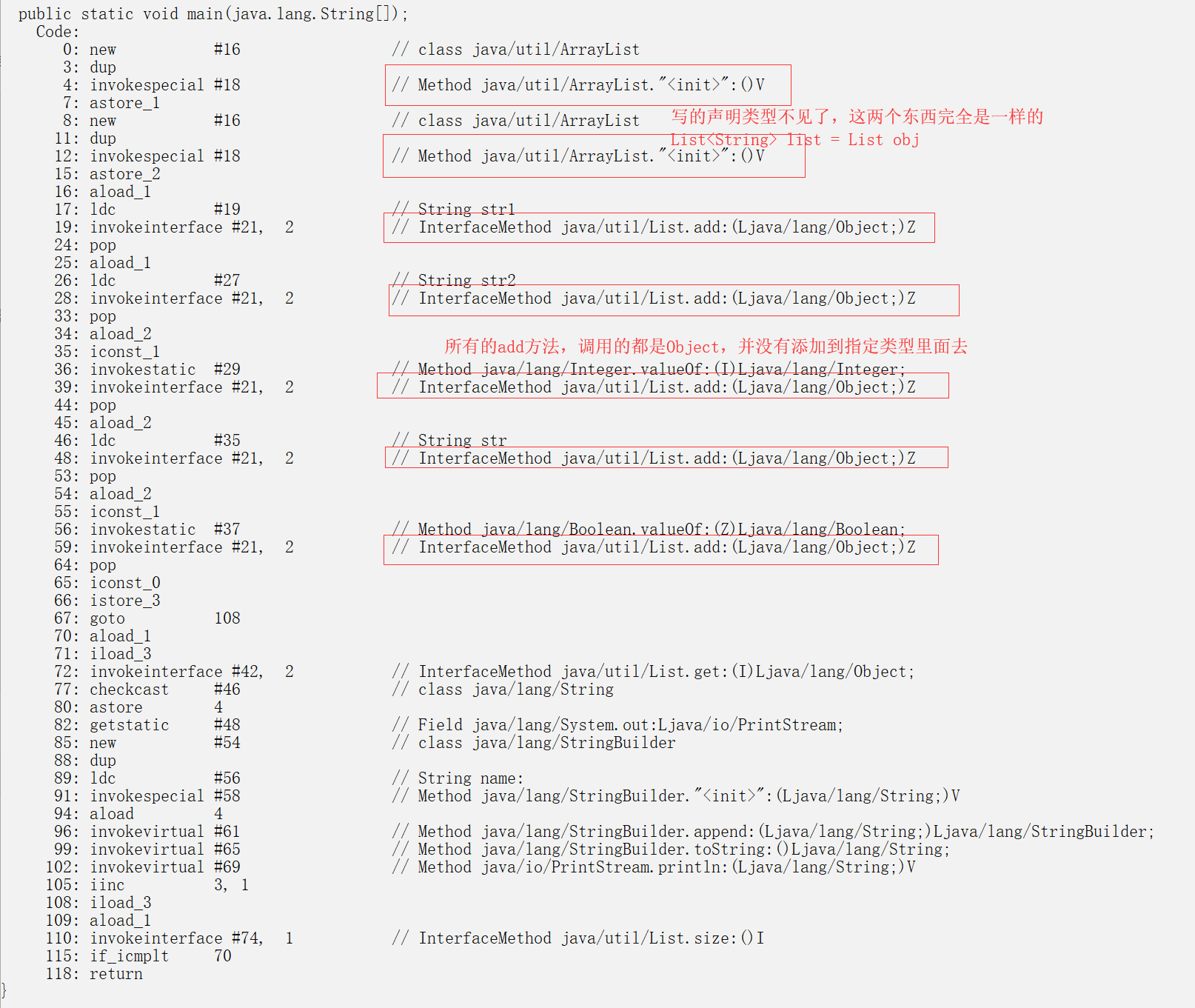
List<String> list = new ArrayList<String>();//<String>声明告诉编译器,这个对象只能添加String类型的
List obj = new ArrayList();//不声明类型,编译器会认为什么都可以添加进来
list.add("str1");
list.add("str2");
obj.add(1);
obj.add("str");
obj.add(true);
for (int i = 0; i < list.size(); i++) {
String name = list.get(i);
System.out.println("name:" + name);
}
}
//发现泛型只是编译器对我们写代码的一种约束,它们机器码都是一样的
//好处就是,编译器给你检测类型对不对
//强化类型安全,由于泛型在编译期进行类型检查,从而保证类型安全,减少运行期的类型转换异常。
}
泛型类
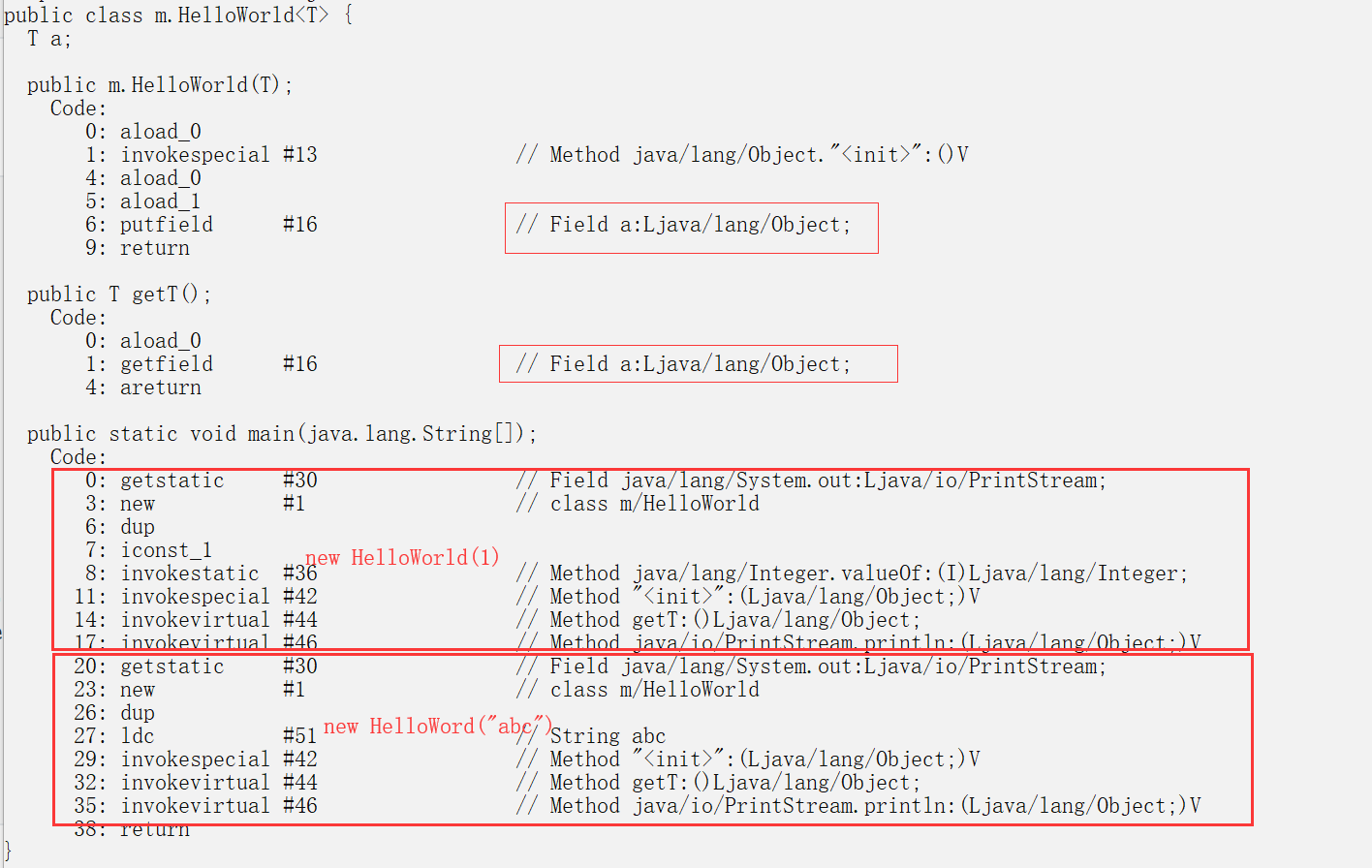
public class HelloWorld<T>{
T a;
public HelloWorld(T t){
this.a = t;
}
public T getT() {
return this.a;
}
public static void main(String[] args) {
System.out.println(new HelloWorld(1).getT());
System.out.println(new HelloWorld("abc").getT());
//想要这个类是String就是String
//想要这个类是int就是int
//但是它的本质都是Obj,它只是一种约束代码规范
//这样写类的好处
//提高代码复用,泛型能减少重复逻辑,编写更简洁的代码
}
}
泛型通配符<?>
当类型T已经被确定的时候,但是类型T里面的方法不想让它是声明的类型
就需要用到了,可以把想象成Object,但是?要比Object强大一点
public void QuestionMark(List<?> list) {
for (List item : list) {
System.out.print(item + " ");
}
//发现这个for循环用的是迭代器
//而枚举同样的写法只是个jump指令
//只要用的类实现了Collection,增强for就会以迭代器的方法实现
//像Map类就不能直接用增强for(使用迭代器)
//Map的存储结构是一种无序数组
强大在可以表示继承某个父类的未知类型,称为泛型上限通配符
//当我们使用QuestionMarkExtendFather时候,使用非继承自Number的对象
//编译器就会提示你在你写的声明中,已经明确指出不接受非Number类型,或Number的子类
public void QuestionMarkExtendFather(List<? extends Number> list) {
for (Number number : list) {
System.out.print(number.intValue()+" ");
}
}
或是表示某个子类的父类,称为泛型下限通配符
//要调用这个方法,传递的对象必须是Interg类型,或者是Interger的父类
public void QuestionMarkBeFather(List<? super Integer> obj){
System.out.println(obj);
}
//这样子定义泛型的好处,类型依赖关系更加明确
泛型方法
//利用泛型方法实例化泛型对象
public class HelloWorld{
public <T> T getObject(Class<T> c) throws InstantiationException, IllegalAccessException{
T t = c.newInstance();
return t;
}
public static void main(String[] args) throws InstantiationException, IllegalAccessException, ClassNotFoundException {
HelloWorld g = new HelloWorld();
Object obj = g.getObject(Class.forName("m.HelloWorld"));
}
}
泛型注意事项
1.一般 K 表示key(键);T表示type(类型);V表示value(值);E表示entry (实体)
如果在类中定义使用泛型的静态方法,需要添加额外的泛型声明(将这个方法定义成泛型方法
Java泛型不能使用原始类型
在Java泛型方法里面不能直接实例化泛型对象的, 就是你传个Hello
,这个String并不能直接New出来。如果需要New出来,那么就需要传入一个Class对象,间接调用(newInstance)实例化出来 Java泛型不能进行类型强转
泛型的本质都是Object,不能用instanceof去进行校验对象
Java泛型不能使用数组
不支持重载,因为写个(String a)或者是(Integer a) 编译器都给你识别成Object,你写的重载方法都会是一样的,Java是不允许在一个类里面写两个一模一样的重载方法的
泛型就是一个编译器类型检测工具,并不影响机器码,怎么写对象都是Object
序列化
在Java里面,类对象要写文件,读文件,都得实现实现序列化接口( Serializable )
题外话: 我每次写C读取结构体的时候是真的累啊, 判断,截取字符串,这一行是否符合规则,要写很多的代码,把硬盘数据加载到内存里面。
而java读写结构体(就是类), 直接一个方法把对象读到内存, 你根本不用管
这个文本的数据合不合法, 一个方法搞定, 管你什么花里胡哨的类,一个方法给你搞定, 你只管调用我这个方法就是了,
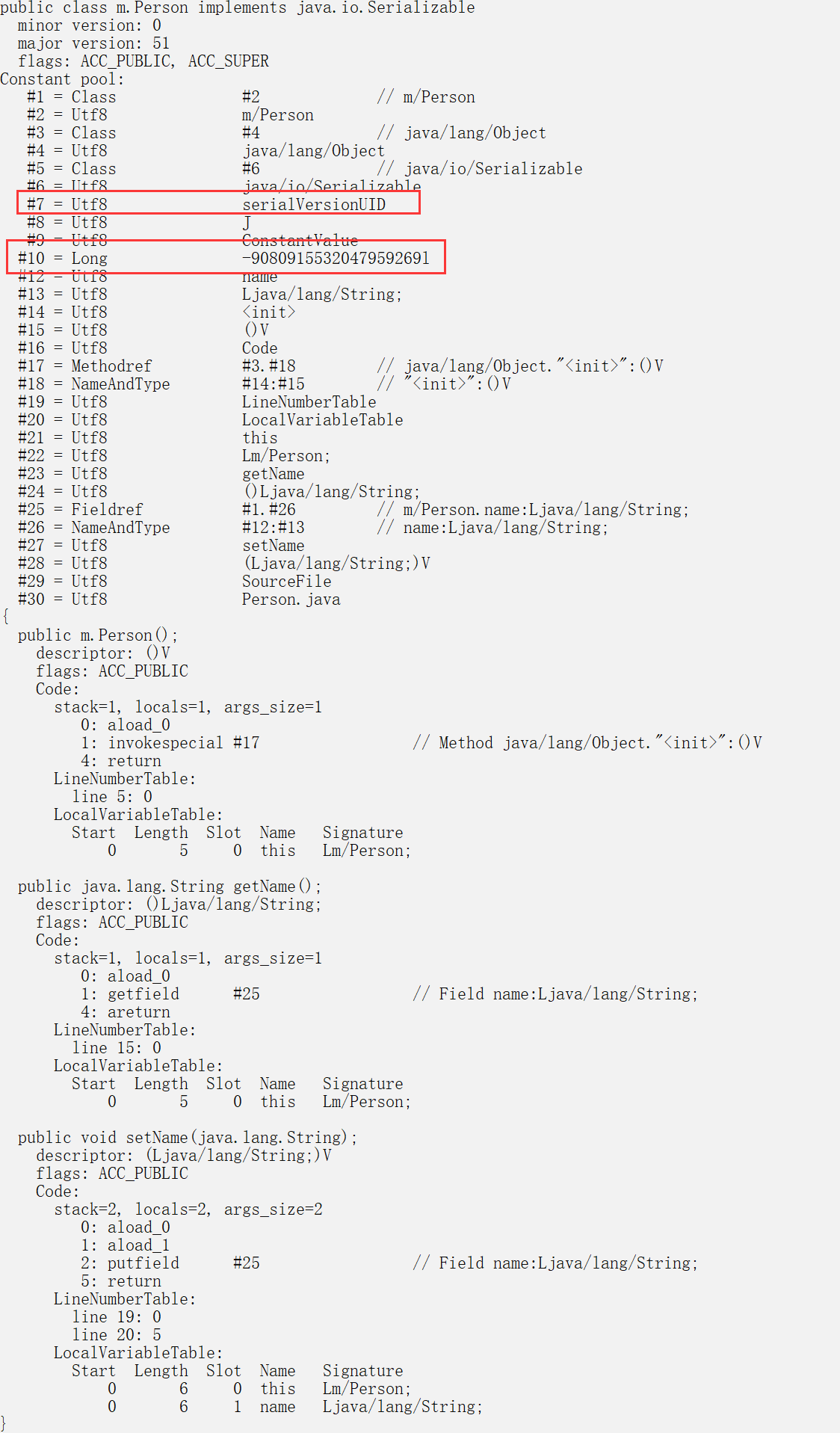
不用担心出错, 当然要是文件错误,它也是会抛出一个结尾符异常的(EOFException)。对比C每个不同的结构体我都要写不同的方法,累啊。在类实现序列化接口后,编译器会要求你生成一个serialVersionUID
所谓的serialVersionUID直白的说就是一个类的版本号。
这个版本号在你读文件的时候, 会用这个版本号对比下是不是同一个版本号,如果要是不符合规则,就会抛出一个无效类的异常(InvalidClassException)。
如果你不写,编译器也会隐性生成一个随机的版本号。这样的目的就是为了让你考虑类版本的问题实现了序列化的类居然只是一个普通的类
import java.io.Serializable;
public class Person implements Serializable {
//serialVersionUID是放在常量池里面,好像和这个类没多大关系啊
private static final long serialVersionUID = -9080915532047959269L;
private String name;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
//发现在readObject有这个方法model.getSerialVersionUID()来获取UID
//获取这个UID有点复杂,它不是直接点出来,完全看不懂
//要写把类写读文件,你就得实现序列化接口,这是Java的强制规定
//实现序列化就是给类加一个版本规范,好像没有别的什么用处了
//机器码很普通没什么截图的
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.ObjectInput;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.io.Serializable;
public class HelloWorld {
public static class SerializationUtil {
private static final String FILE_NAME = "D:/obj.txt";
//写入文件
public static void writeObject(Object s) {
try {
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream(FILE_NAME));
oos.writeObject(s);
oos.close();
} catch (Exception e) {
e.printStackTrace();
}
}
//读取文件
public static Object readObject() {
Object obj = null;
try {
ObjectInput input = new ObjectInputStream(new FileInputStream(FILE_NAME));
obj = input.readObject();
input.close();
} catch (Exception e) {
e.printStackTrace();
}
return obj;
}
}
public static void main(String[] args) {
// 序列化
Person person = new Person();
person.setName("1234");
SerializationUtil.writeObject(person);
Person p = (Person) SerializationUtil.readObject();
System.out.println("name = " + p.getName());
}
}注解节省代码
注解就是注释,但是比注释更强大,编译器是能理解你写的注释的
注解可以分两种:
1.写给编译器的规则,并不会影响代码。
2.写给类,方法的约束条件,这种东西就会影响代码,编译器根据你写的注解方法,条件,机械式生成机器码。
注解你写一个声明就是了,然而实现它却是很复杂的.
注解虽然表面上节省了大量代码,实际上编译器确要干很多事情
注解貌似只有java才有,缺点就是这就是专门为java编译器写,对于别的语言的帮助对我来说感觉不到
注解节省的代码量相对于理解成本我觉得这是值得的,一句注解就能让编译器按你的规则帮你写代码不会影响机器码的注解,相当于手写的编译器提示
@Override//使用这个注解后,这里编译器就会提示你,这不是一个父类方法,你不是在重写函数,你是在新增一个方法
public String tostring() {//故意把toString写成了tostring
return "123";
}
重写方法的时候一定要加这个@Override吗?
1.不用,这个时候注解就相当于一个注释了,这是一个编译器规则
2.让别人一看这个注解,哦,这是一个重写方法
如何区分注解会不会影响代码呢?
1.通过查看注解源码的声明,点开Override.class,你会看到这么两个注解
@Target(ElementType.METHOD)//位置(用于节点的方法)
@Retention(RetentionPolicy.SOURCE)//作用域(编译时会丢弃)
几乎所有的注解都会有这么两个声明
注解用在哪啊(点进ElementType看看注释, 有11个类型(用的是JavaSE-10))
注解的物理作用域(点进RetentionPolicy, SOURCE, CLASS, RUNTIME)
2.对比编译出来的字节码
3.使用反编译工具,看看有没有注解
@Override没有被编译进字节码文件里面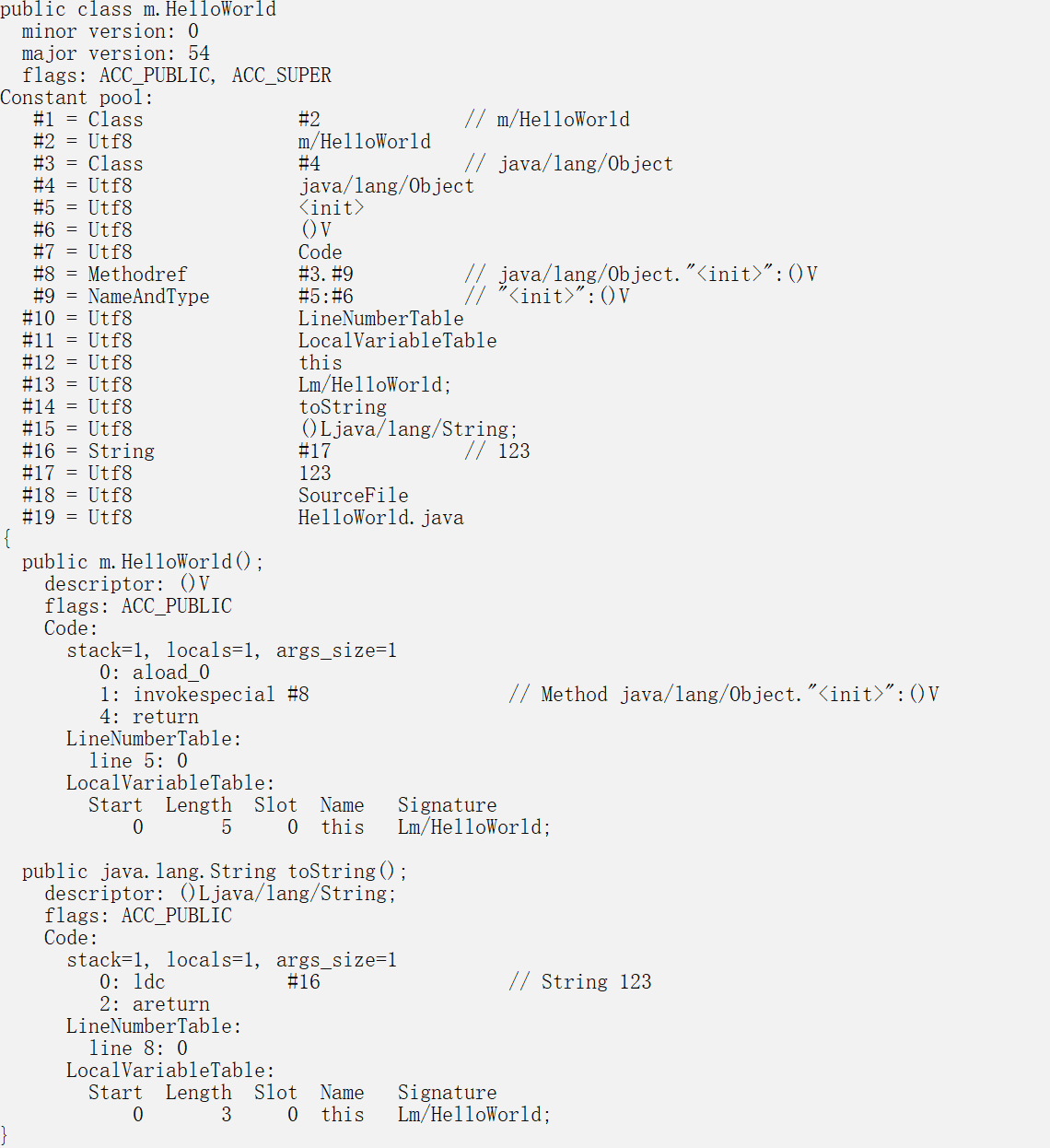
(RetentionPolicy)注解的物理作用域
SOURCE: 只存在于书写的代码,编译成字节码的时候自动忽略(无法保存的注释)
CLASS: 它是默认的物理作用域值,存在于书写的代码和机器码里面(可以阅读的注释,但是java方法读不到)
RUNTIME: 存在于书写的代码和机器码里面,并且还可以通过java方法给读出来,这也是用的最多的(可以执行的注释)会影响机器码的注解
@Deprecated//这个注解的意思是告诉编译器这是一个过时的东西
public String toString() {
return "123";
}
//常常使用Date类方法就会提示这个注解
//它的作用域是@Retention(RetentionPolicy.RUNTIME)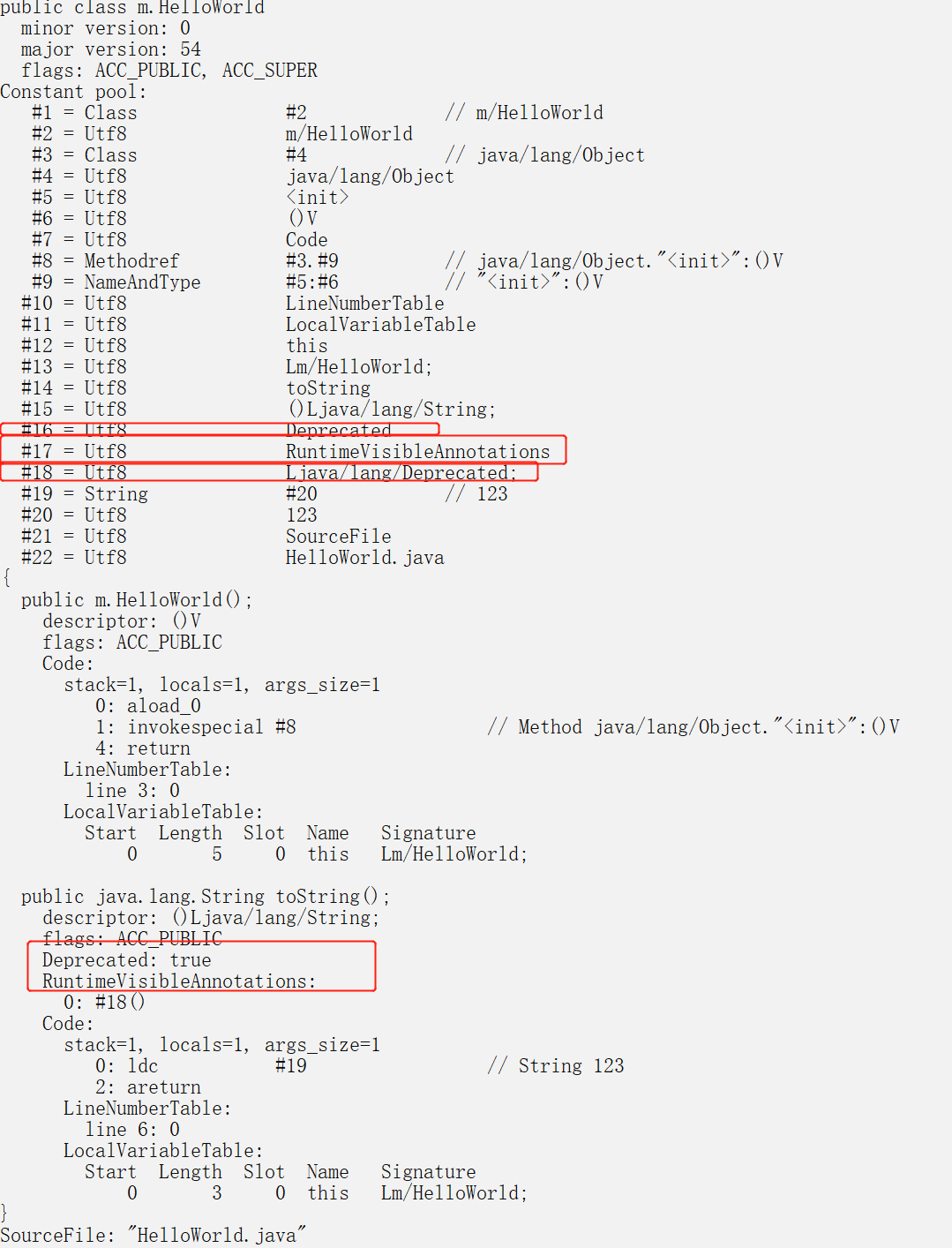
注解编进字节码的好处
最常使用的@Test注解,只要在函数上面写一个这样的注解就可以免写静态main函数
右键点击就可以执行@Test的函数,@Test是如何做到的呢?
在java里面提供了一种读取类的方法Class.forName(“类的名称”),返回Class对象
注意:Class.forName()会自动帮你执行类里面的静态代码块。
Class对象我是理解成一个万能的java类对象结构体,通常叫类反射
可以通过Class方法拿到对应类里面的所有东西(方法,对象,注解等等)
@Test就是通过这种方法,加载Class然后在Class找到对应的方法,执行
貌似感受不到注解的强大啊,貌似我用的注解大多用于web开发
通常是一个请求对应一个方法,不用注解就得搞个配置文件来映射链接和方法
还有我们用的 service通常都是单例的,也就是说我们的对象只用生成一次
如果上面两个都用注解解决的话可以节省很多的代码量
我们最常用的web工具包spring就是这样利用注解节省了大量的代码,
请求=>把注解和链接写在方法上就是了, 单例对象=>注解声明一下对象,
spring通过注解,和配置文件把想要的类给初始化
注解对于那些机械式代码,但是又要人去写,非常有用, 这也可以说是语言的设计缺陷(有的语法实在是太啰嗦了)
String与StringBulider和StringBuffer
在java里面,一个字符串类型居然可以玩出这么多花样,为什么要搞那么多类型?
String在java里面是作为一个基础类型,不需要new,而且是final类型的。
StringBulider和StringBuffer是要new出来,是有默认大小的,属于工具类型。
java很重要的一点,它是不允许直接操作内存地址的, 这就是导致了字符串难以修改。
要修改字符串怎么办,再分配一块内存。3种类型各有应用场景。
String类型的设计就是单纯保存一个字符串,就是不准修改了。
StringBulider的类型设计就是为了增删修改字符串而出现的。
StringBuffer的类型设计就是为了多线程增删字符串而出现的。
如果要是直接用StringBulider替换String,很容易造成内存的浪费。
JAVA内存常见问题
内存溢出
指你申请了8个字节的空间,但是你在这个空间写入9或以上字节的数据,就是溢出
java程序的内存划分
栈(基本数据类型、引用数据类型变量名)、
堆(引用数据类型变量值,传递的是地址,String是特殊的用数据类型,值不可变) 、
全局代码区(方法包括静态方法,共享设计模式)、
全局数据区(static静态属性为整个对象所共有,共享设计模式)1.我们写的程序是交给JVM运行的,并不是直接交给系统
2.java里面也没有malloc这样的函数,貌似它就不用担心内存没有被释放的问题,但是我们可以写个线程不断new啊。
超过GC开销限制 , 然后死机, 我们new的对象是放在堆里面的, 属于堆溢出3.java读取文件,链接的时候,这个文件链接有1个G怎么办呢?
OutOfMemoryError, 然后死机, 读的数据也是放在堆里面,属于堆溢出4.在Java程序里面写个无限递归,造成栈溢出怎么办
StackOverflowError, 然后死机, 因为栈也是有大小限制的栈溢出
//Exception in thread "main" java.lang.StackOverflowError
public class HelloWorld{
public static int c = 0;
public static void main(String[] args) {
HelloWorld h = new HelloWorld();
h.testStackOverflowError();
}
public void testStackOverflowError() {
System.out.println(c++);
testStackOverflowError();
}
}堆溢出
//Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
import java.util.ArrayList;
import java.util.List;
public class HelloWorld{
public static int i = 0;
public static List<String> list = new ArrayList<String>();
public static void main(String[] args) {
HelloWorld h = new HelloWorld();
h.addString();
}
public void addString() {//OutOfMemoryError
while (true) {
System.out.println(i++);//
String s = "1234567890abcdefghijklmn";
list.add(s);
}
}
}总结:内存溢出是一定存在的,因为栈和堆都是有大小限制的。不要有无限增加内存, 估算好JVM内存空间。这样去避免内存泄露, 递归虽然强, 错误的递归死机也很快。
内存泄露
new申请了一块内存,但是没有释放,导致这块内存一直处于占用状态
Java的一个重要特性就是通过垃圾收集器(GC)自动管理内存的回收,而不需要程序员自己来释放内存。理论上Java中所有不会再被利用的对象所占用的内存,都可以被GC回收,但是Java也存在内存泄露,但它的表现与C++不同。 GC是如何释放内存的
GC会监控每一个对象的状态,包括申请、引用、被引用和赋值等。
释放对象的根本原则就是对象不会再被使用给对象赋予了空值null,之后再没有调用过。
另一个是给对象赋予了新值,这样重新分配了内存空间。对象生命周期引发的内存泄露
对象都是有生命周期的,有的长,有的短,如果长生命周期的对象持有短生命周期的引用,就很可能会出现内存泄露。
例题:
public class HelloWorld {
Object object;
public void method(){
object = new Object();
//我们期望在执行method后就把new Object释放掉
//但是GC检测到它还被Object引用,就要等到程序结束才释放
//好像不会影响什么大错啊
//要想及时释放 object = null;就可以了
}
}
//如果在删除内存结点的时候,不释放那就有大错了
public E pop(){
if(size == 0)
return null;
else{
E e = (E) elementData[--size];
//这里的elementData[--size]的内存没有释放掉
//后果就是这块无效内存一直被占用,除非e = null GC才会释放
//但是就想要释放这一小块内存怎么办
//elementData[--size] = null GC就可以去释放这块内存
return e;
}
}
//只要有对象在引用,那么GC就不会去释放内存
//我们在写代码的时候要考虑下类的生命周期,它有没有被外部类引用,能不能及时释放汇编与C++
c++是对c的扩充,条件,变量类型和逻辑其实都差不多就不做测试了
操作系统win10, C++, 编译工具VS 2019
引用的本质
#include <iostream>
using namespace std;
int main()
{
int i = 10;
int& j = i;
int k = 10;
printf("&i:%d===&j:%d==&k:%d", &i, &j, &k);
//打印结果& i:-2086994656 == = &j : -2086994656 == &k : -2086994652
return 0;
}发现 i和j的地址是相同的,也就是说改变i的值就会改变j的值
引用就是把需要引用对象的偏移地址拿过来保存
面向对象
#include <iostream>
using namespace std;
typedef unsigned int u32;
class Box
{
public:
double length; // 盒子的长度
protected:
double width; // 盒子的宽度
private:
double height; // 盒子的高度
public:
void setArgs(u32 length, u32 width, u32 height)
{
this->length = length;
this->width = width;
this->height = height;
}
public:
u32 getVolume()
{
return length * width * height;
}
};
class publicTable: public Box
{
//继承时保持基类中各成员属性不变,并且基类中private成员被隐藏。
//派生类的成员只能访问基类中的public/protected成员,而不能访问private成员;
//派生类的对象只能访问基类中的public成员。
};
class privateTable: private Box
{
//继承时基类中各成员属性均变为private,并且基类中private成员被隐藏。
//派生类的成员也只能访问基类中的public/protected成员,而不能访问private成员;
//派生类的对象不能访问基类中的任何的成员。
};
class protectedTable: protected Box
{
//继承时基类中各成员属性均变为protected,并且基类中private成员被隐藏。
//派生类的成员只能访问基类中的public / protected成员,
//而不能访问private成员;派生类的对象不能访问基类中的任何的成员。
};
//无论哪种继承,private只能被初始的那个类访问,初始类的儿子都不能访问
//protected 只供自己和派生访问
//public 所有人 protected 内部使用/继承使用 private 只能自己一个类内部使用
int main()
{
Box box1;
Box box2;
//protected不支持box1.width = 1;
//private不支持box2.height = 1;
box1.setArgs(2, 2, 2);
box2.setArgs(3, 3, 3);
printf("box1 Volume:%d ====box2 Volume:%d ", box1.getVolume(), box2.getVolume());
publicTable t1;
t1.length = 10;
privateTable t2;
protectedTable t3;
//t2和t3都无法访问基类的任何成员包括方法,一旦使用编译器就会提示错误
system("pause");
}
类的变量压根没有占有段地址空间,直接编写在代码里面,占用的空间都在栈上面。
不知道其他语言是不是这样做的,没有用到的类是没有编进去的。
虚函数virtual
类似java里面的接口的抽象方法,实现了该接口就要求你实现该接口里面的抽象方法,C++就是这样
#include <iostream>
using namespace std;
class Shape {
protected:
int width, height;
public:
Shape(int a = 0, int b = 0)
{
width = a;
height = b;
}
virtual int area()
{
cout << "Parent class area :" << endl;
return 0;
}
};
class Rectangle : public Shape {
public:
Rectangle(int a = 0, int b = 0) :Shape(a, b) { }
int area()
{
cout << "Rectangle class area :" << endl;
return (width * height);
}
};
class Triangle : public Shape {
public:
Triangle(int a = 0, int b = 0) :Shape(a, b) { }
int area()
{
cout << "Triangle class area :" << endl;
return (width * height / 2);
}
};
// 程序的主函数
int main()
{
Shape* shape;
Rectangle rec(10, 7);
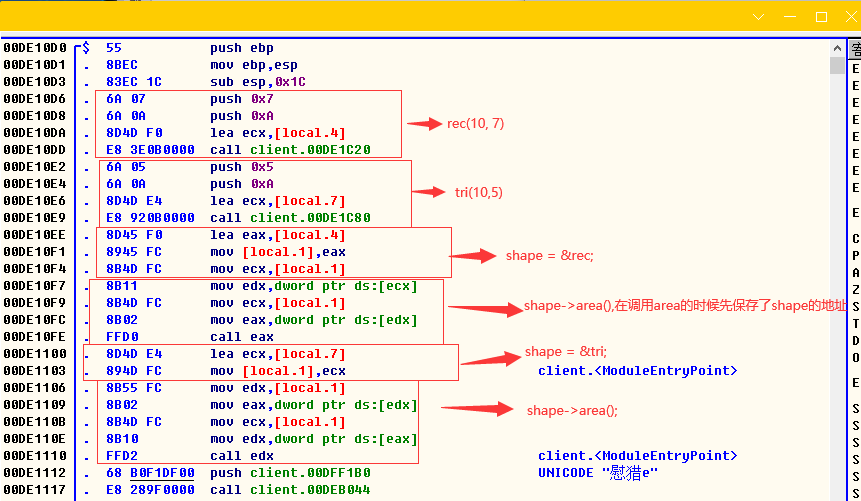
Triangle tri(10, 5);
// 存储矩形的地址
shape = &rec;
// 调用矩形的求面积函数 area
shape->area();
// 存储三角形的地址
shape = &tri;
// 调用三角形的求面积函数 area
shape->area();
return 0;
}

重载方法与重载运算符
c++的函数重载基本和别的语言一样,根据类型自动匹配方法
重载运算符这个东西感觉很创新
#include <iostream>
using namespace std;
class Box
{
public:
int getVolume(void)
{
return length * breadth * height;
}
void setArgs(int length, int breadth, int height)
{
this->length = length;
this->breadth = breadth;
this->height = height;
}
// 重载 + 运算符,用于把两个 Box 对象相加
Box operator+(const Box& b)
{
Box box;
box.length = this->length + b.length;
box.breadth = this->breadth + b.breadth;
box.height = this->height + b.height;
return box;
}
void showBox()
{
printf("length:%d==breadth:%d==height:%d\r\n", this->length, this->breadth, this->height);
}
private:
int length; // 长度
int breadth; // 宽度
int height; // 高度
};
// 程序的主函数
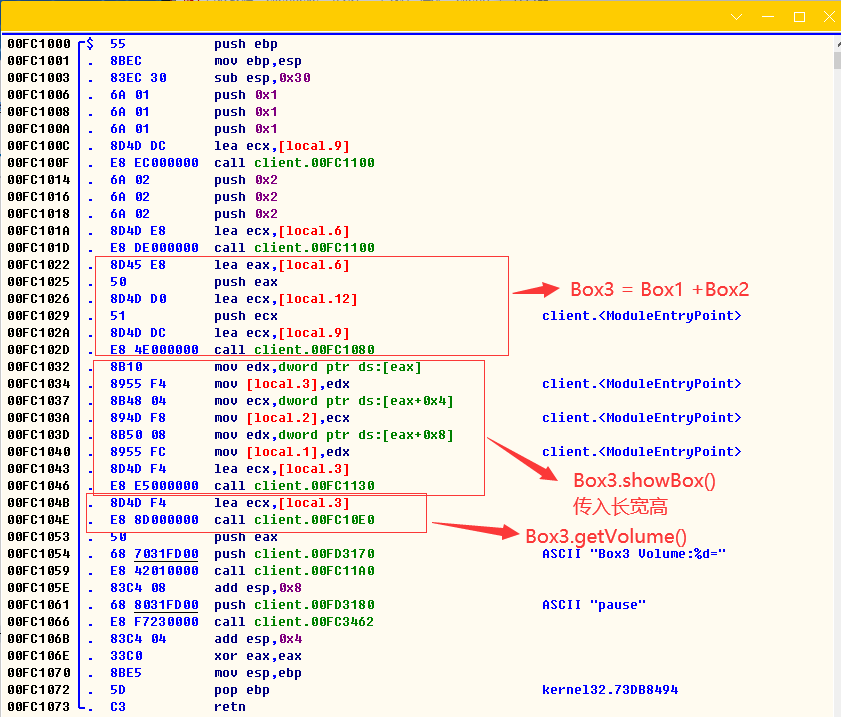
int main()
{
Box Box1; // 声明 Box1,类型为 Box
Box Box2; // 声明 Box2,类型为 Box
Box Box3; // 声明 Box3,类型为 Box
Box1.setArgs(1, 1, 1);
Box2.setArgs(2, 2, 2);
Box3 = Box1 + Box2;
Box3.showBox();
printf("Box3 Volume:%d=", Box3.getVolume());
system("pause");
return 0;
}
new 和 delete本质
它和C里面的malloc的free是否有区别呢?
#include <iostream>
using namespace std;
int main()
{
int* pvalue = NULL; // 初始化为 null 的指针
int* cvalue = NULL;
pvalue = new int; // 为变量请求内存
cvalue = (int*)malloc(4);
*pvalue = 16; // 在分配的地址存储值
*cvalue = 8;
cout << "pvalue : " << *pvalue << " cvalue: " << *cvalue << endl;
delete pvalue; // 释放内存
free(cvalue);
system("pause");
return 0;
}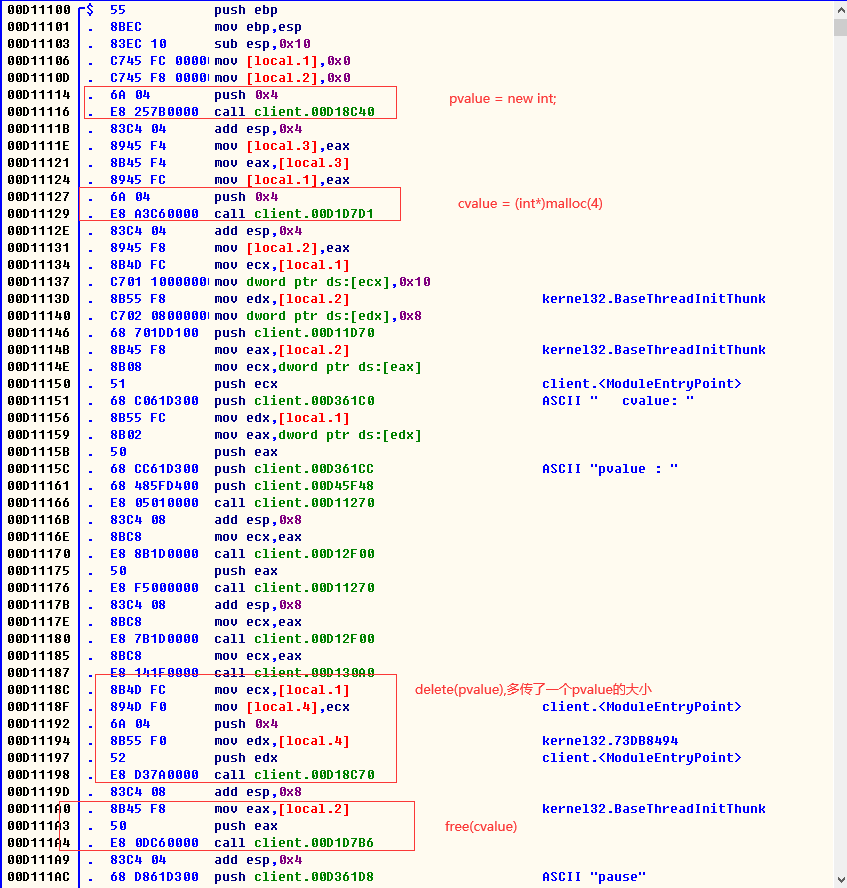
说实话看我不出什么区别
new和delete是malloc和free的规范升级版,编译器自带的功能,不需要引入头文件
最大的不同应该是new和delete对类的释放和销毁有自己一套规则
感觉这两个关键字就是为了类而发明的
汇编与Python
操作系统win10, Python3.6, 编译工具VS 2019
Python类似JAVA,不过Python的语法更加精辟,py文件编译产生pyc字节码(在控制台写入少量的代码
默认是不生成文件和字节码的,直接在内存里面完成解释执行),Python虚拟机负责执行字节码。
def hello():
print("Hello World!");
import dis
dis.dis(hello)
Python的等于号
def test():
a = b = 1<<10;
c = 10.1234567891234;
d = "str";
a = c;
c = d;
d = a;
print(a);
print(b);
print(c);
print(d);
import dis
dis.dis(test)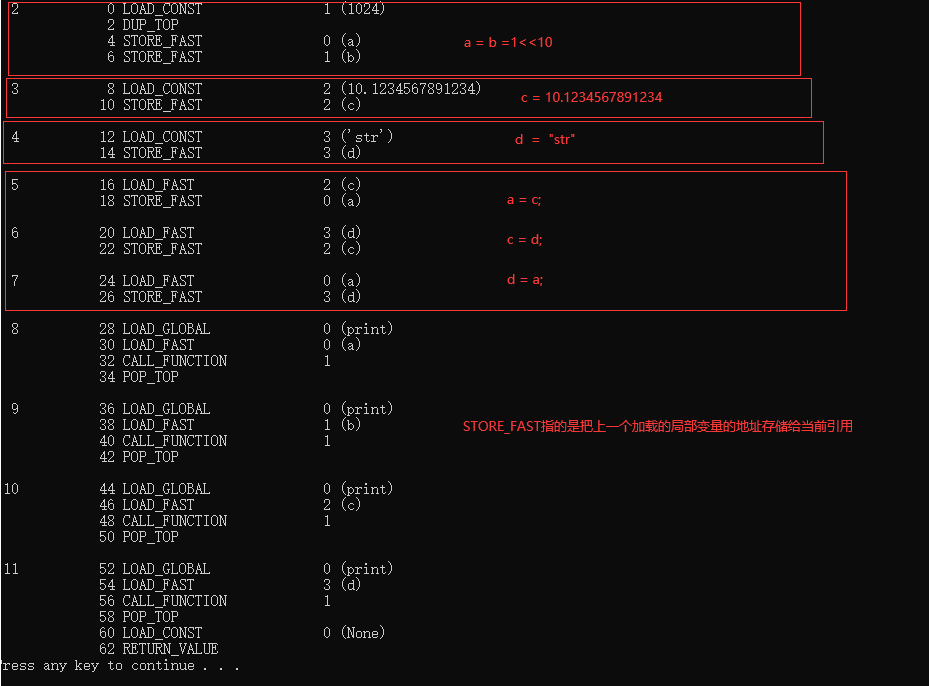
python的等于号不同于JAVA,C,C++,它要做的就是把变量引用的位置给改变。
不会真正的进行类型转换。如果要转换需要执行Python对于的类型转换函数
# int(x[, base]) 将x转换为一个整数,base为进制,默认十进制
#
# long(x[, base] ) 将x转换为一个长整数
#
# float(x) 将x转换到一个浮点数
#
# complex(real[, imag]) 创建一个复数
#
# str(x) 将对象 x 转换为字符串
#
# repr(x) 将对象 x 转换为表达式字符串
#
# eval(str) 用来计算在字符串中的有效Python表达式, 并返回一个对象
#
# tuple(s) 将序列 s 转换为一个元组
#
# list(s) 将序列 s 转换为一个列表
#
# set(s) 转换为可变集合
#
# dict(d) 创建一个字典。d 必须是一个序列(key, value) 元组。
#
# frozenset(s) 转换为不可变集合
#
# chr(x) 将一个整数转换为一个字符
#
# unichr(x) 将一个整数转换为Unicode字符
#
# ord(x) 将一个字符转换为它的整数值
#
# hex(x) 将一个整数转换为一个十六进制字符串
#
#oct(x) 将一个整数转换为一个八进制字符串元组,列表,字典
def test():
list = ['AAA','BBB','CCC','DDD']
#元组是只读的,值不可改变
tuple = ('AAA','BBB','CCC','DDD')
dict = {'name':'AAA','code':'BBB','dept':'CCCC'}
list[0] = 'BBB'
#错误 tuple[0] = list[0];
dict['name'] = "AAA"
dict[1] = "BBB"
import dis
dis.dis(test)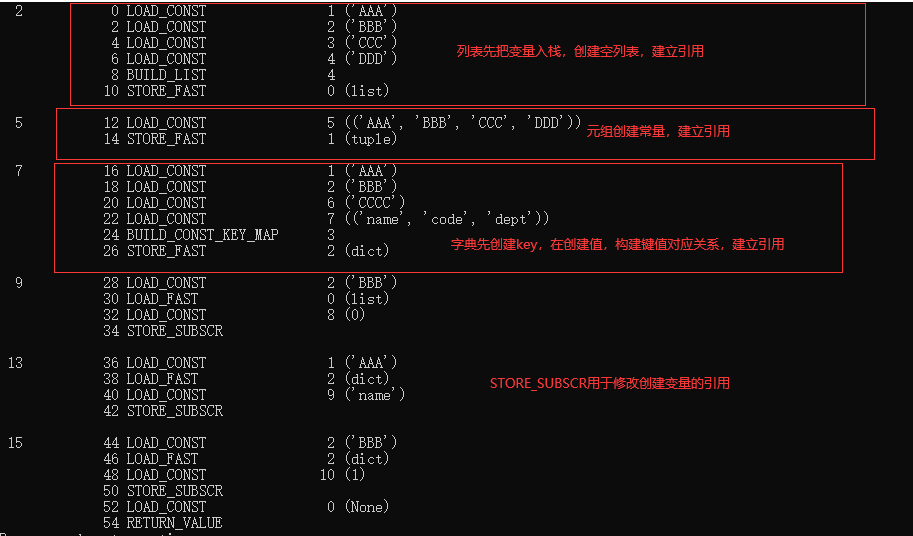
条件和跳转
def test():
num = 5
if num == 3: # 判断num的值
print(num)
elif num < 0: # 值小于零时输出
print(num)
else:
print(num) # 条件均不成立时输出
while(1):
print(num)
for letter in 'Python': # 第一个实例
if letter == 'h':
break
if letter == 'h':
continue
if letter == 'h':
pass
print("当前字母 :"+letter)
import dis
dis.dis(test)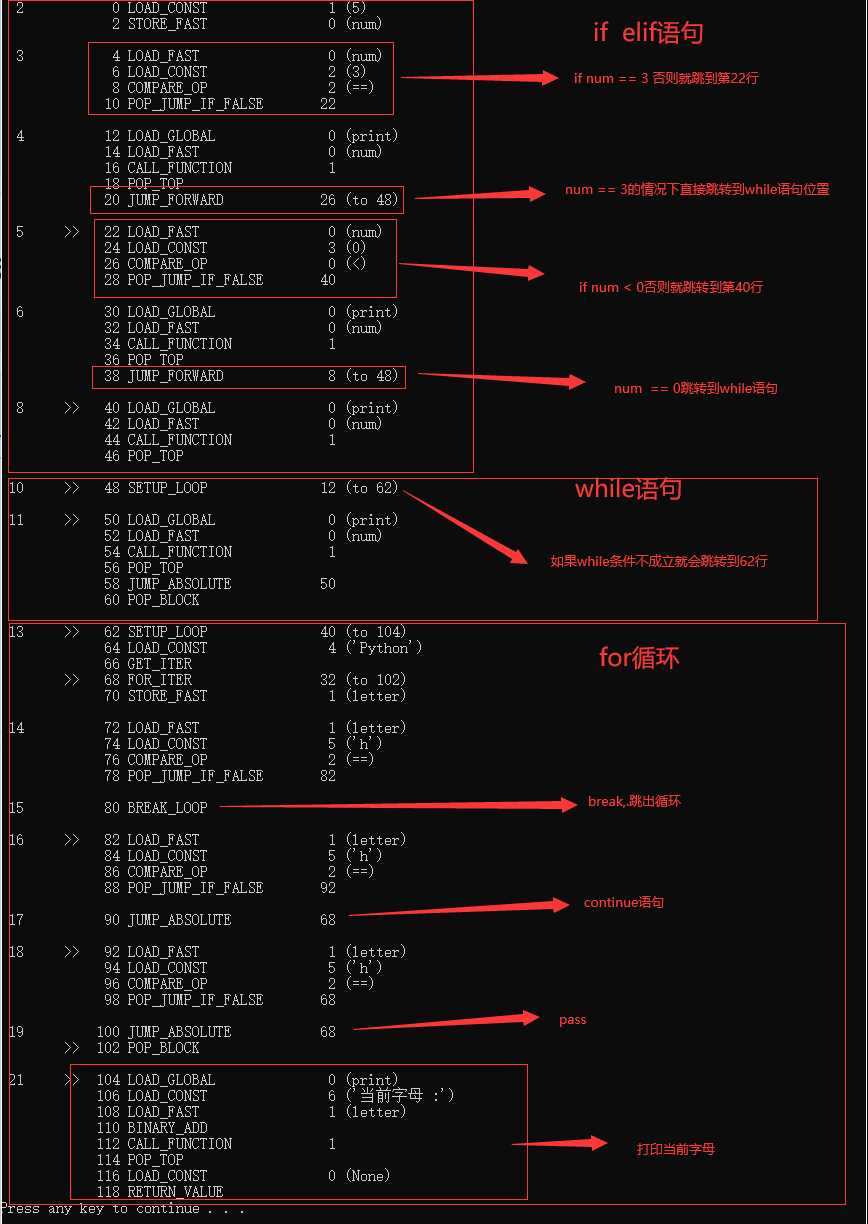
pass和continue的区别,在循环体里面它们是一样的
但是pass不在循环体而在函数内意思是直接函数返回
函数传递参数
python不直接提供指针,也就是说无法直接修改变量所指向的内存空间的值
def point(a):
a = 100;
print(id(a))
return;
b = 10;
point(b)
print(id(b));
#输出结果为10,函数参数a只是个拷贝
#a 和 b的地址为两个不同的地址
def changeList(list):
list[0] = "a";
list[1] = "b";
list[2] = "c";
print(id(list));
return;
numList = [1,2,3];
changeList(numList);
print(numList);
print(id(numList));
#numList = ["a","b","c"];
#numList 和list的值为同一个地址
import dis
dis.dis(point)
dis.dis(changeList)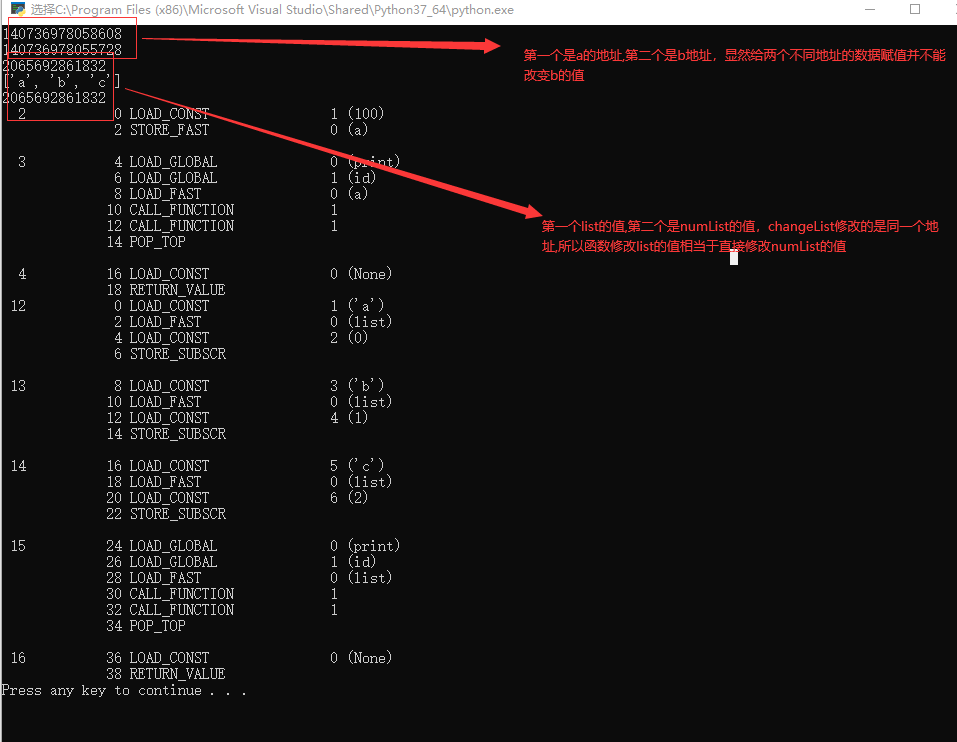
类的本质
class Employee:
empCount = 0
def __init__(self, name, salary):
self.name = name
self.salary = salary
Employee.empCount += 1
def displayCount(self):
print("Total Employee %d" % Employee.empCount);
def displayEmployee(self):
print("Name : ", self.name, ", Salary: ", self.salary);
def test():
emp = Employee("pika",5000);
empx = Employee("pika",5000);
print(id( emp));
print(id( empx));
print(id( emp.displayCount));
print(id( empx.displayCount));
print(id( emp.displayEmployee));
print(id( empx.displayEmployee));
return;
test();
import dis
dis.dis(Employee)
dis.dis(test)
发现很多什么高级语言提出的对象本质就是
对象 = 基础变量 + 对象的方法
类的构建 = 创建基础变量 + 执行初始化方法
每构建一个对象,会为对象的值分配地址,对象的值是分开放的,
而对象的方法是放在一个地方,反复利用
python对象的返回值不写默认为0
python还有方法重载,重写,私有,继承某些东西和Java都差不多
继承是一种对结构体和方法的扩展
内存的释放
支持手动和自动释放,高级语言都是重复的东西都用一个地址保存, 把所有的引用释放了,
才能把内存空间的所有权释放掉
汇编与C sharp
C sharp是一门面向对象的语言,C#是C和C++的语法简化版本, 复杂的底部东西编译器帮你搞定
using System;
namespace ConsoleApp1
{
class Program
{
static void Main(string[] args)
{
int a = 100;
Console.WriteLine("Hello World!");
}
}
}
Object 和 dynamic 和 var 和 数字类型转型
using System;
namespace ConsoleApp1
{
class Program
{
static void Main(string[] args)
{
int test = 16;
Object obj1, obj2;
obj1 = 100;
obj2 = "a";
dynamic a = "b";
a = 100.1;
var c = 100;
int aint = (int)a;
Console.WriteLine("obj:{0} dynameic:{1} aint:{2} ", obj1, a, aint);
}
}
}
这里我只看到字符是存在段地址里面,其它一概看不懂。
它不像C和C++那么简单,中间还做了很多事情,也不知道目的是什么。
Object不能绕过编译器的类型检测,dynamic可以做到, 而var只是个简单的根据值来填充类型
dynamic 和object的赋值是非常接近的,obj强制转型的时候,dynamic会隐性帮你做
面向对象的深刻理解
刚开始,对象的本质在我眼里就是结构体加上公共方法没啥了不起的,
不就是编译器帮你编译时多干些活,把这些初始化方法自动编进去的。
当我结构体和方法写多了后,现在发现结构体和方法联合起来就是一种跨时代的思想创新
什么样的方法就该用什么样的结构体或者说是什么样的结构体就该用什么方法。
在一个大代码工程里面,面向对象可以明确区分功能区,组件化思想,
在设计程序的时候可以想的更深
